Results of the Computational Chemistry Commune 2024 poll on the popularity of computational chemistry programs and DFT functionals
文/Sobereva@北京科音 2024-May-5
0 前言
2024年4月4號,在北京科音建立的人氣最高、專業性最強的綜合性計算化學論壇“計算化學公社”(http://bbs.keinsci.com)上開展了為期一個月的五項投票:
你最常用的做量子化學計算的DFT泛函投票(http://bbs.keinsci.com/thread-44387-1-1.html)
你最常用的做第一性原理計算的DFT泛函投票(http://bbs.keinsci.com/thread-44391-1-1.html)
你最常用的量子化學程序投票(http://bbs.keinsci.com/thread-44388-1-1.html)
你最常用的分子動力學程序投票(http://bbs.keinsci.com/thread-44389-1-1.html)
你最常用的第一性原理程序投票(http://bbs.keinsci.com/thread-44390-1-1.html)
現對投票結果進行總結和簡單評論。未來預計每三年重新開展一次投票。要強調的是,這個投票只是體現流行程度,和方法/程序的好壞并沒直接關系。本投票結果主要反映中國的計算化學領域的專業、內行群體的情況,不反映業余/外行群體的情況。本次投票的結果也有助于業余/外行研究者正確認清什么才是主流,減少被他人忽悠、聽信歪曲說辭誤入歧途的概率。
上一次的投票于2021年舉行,當時的結果和很多相關評論見下文:
2021年計算化學公社論壇“你最常用的計算化學程序和DFT泛函”投票結果統計
http://www.shanxitv.org/599(http://bbs.keinsci.com/thread-23482-1-1.html)
1 你最常用的做量子化學計算的DFT泛函投票
本次可投的泛函有43種,帶不帶色散校正算同一種泛函。在2021年的投票條目基礎上有所增減,特別是增加了雙雜化泛函,明顯幾乎不會有人用的泛函沒納入可投范圍。投票范疇僅限做量子化學計算的情況,不包含第一性原理計算的情況。關系特別近的,比如M05-2X和M06-2X、wB97X和wB97XD和wB97X-D3、SCAN和r2SCAN、revDSD-PBEP86-D3(BJ)和DSD-PBEP86-D3(BJ)等等當做同一個泛函來計。此次投票者共713人。本投票每個人最多選6項,且所投的泛函必須占平時全部研究工作的5%以上。按照得票率(票數除以總投票人數)繪制的圖如下。為了避免條目過多,只把得票前30名的列出。此圖中諸如某泛函對應50%就代表有50%的人平時較多使用此泛函,后文的統計圖同理。
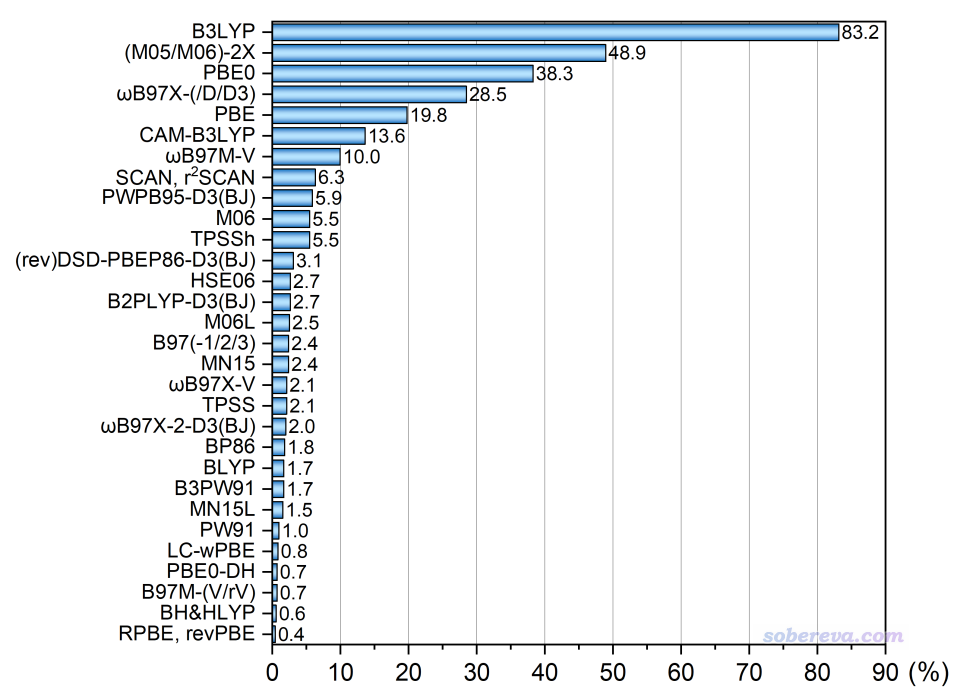
總的來說本年度的投票結果和2021年時沒太大變化,前六名的順次沒有改變,還是依次為B3LYP、(M05/M06)-2X、PBE0、wB97X-(/D/D3)、PBE、CAM-B3LYP老幾樣,各自有各自的用處(參看我對2021年投票結果的評論http://www.shanxitv.org/599,這里不再贅述)。它們的得票率的相對比例也基本沒變,也就是量化領域里用處相對有限的PBE的比例有一定降低,以后肯定還得跌。2021年時候的第7名M06雖然得票率如今還是5%左右,但排名已下滑到第10,被wB97M-V、SCAN/r2-SCAN、PWPB95-D3(BJ)所超過。M06在我來看用處著實不大,雖然計算過渡金屬配合物體系有一定用處,但PBE0-D3(BJ)/D4多數情況是更好的選擇,而且M06還有后繼者MN15可用。wB97M-V的得票率從2018年的3.1%提升到了如今的10%,已經算是增幅很快了,再過3年統計時肯定還會增高。此泛函在國內量化研究者中一定程度的流行,很大程度在于在計算化學公社論壇和思想家公社QQ群的討論中時常被提及、在《簡談量子化學計算中DFT泛函的選擇》(http://www.shanxitv.org/272)博文中和我在北京科音基礎(中級)量子化學培訓班(http://www.keinsci.com/workshop/KBQC_content.html)中的推薦、被免費的ORCA程序支持。提出時間不算很長的純泛函SCAN及其改進版r2SCAN現在得票率能到6%著實不容易,2021年時得票率還不到1%,這主要在于有越來越多的程序已經支持此泛函,而且綜合素質整體強于更早的經典泛函PBE,因而在純泛函范疇內能有重要的位置。
2021年投票的時候沒納入雙雜化泛函,這次得票率超過1%的雙雜化泛函的排名順序是PWPB95-D3(BJ)(5.9%) > (rev)DSD-PBEP86-D3(BJ)(3.1%) > B2PLYP-D3(BJ) (2.7%) > ωB97X-2-D3(BJ) (2.0%)。PWPB95-D3(BJ)和(rev)DSD-PBEP86-D3(BJ)能在國內用戶中變得流行和上述wB97M-V的情況很類似。本身這倆泛函各有長處,有流行開來的必然性。PWPB95-D3(BJ)比較robust,算過渡金屬配合物能量問題較好,能在ORCA里用;而revDSD-PBEP86-D3(BJ)算主族體系反應能、勢壘以及弱相互作用能都是雙雜化里頂尖的,而且在Gaussian里通過《Gaussian中非內置的理論方法和泛函的用法》(http://www.shanxitv.org/344)我介紹的方法能直接用。此外,ORCA中DSD-PBEP86適合算TDDFT和NMR目的也是其加分項。這倆泛函現在流行度能超過經典且最早提出的雙雜化泛函B2PLYP是其應得的。
BLYP這次的排名降幅很大,從第10名已跌到第22名,本身這個泛函如今鮮有用武之地。BLYP一般也就算算主族體系,在Gaussian里用這個明顯不如用B3LYP,耗時也持平,而以前在ORCA里用這個搭配def2-SVP結合RIJ加速做有機體系幾何優化速度效率高是個用處,以前我在《大體系弱相互作用計算的解決之道》(http://www.shanxitv.org/214)里也提過,但如今也不如改用B97-3c來跑。
2 你最常用的做第一性原理計算的DFT泛函投票
可投的泛函有26種,帶不帶色散校正算同一種泛函。此投票在2021年沒有,是本次新加的。此次投票者共442人。本投票每個人最多選6項,且所投的泛函必須占平時全部研究工作的5%以上。結果如下,零票的未顯示
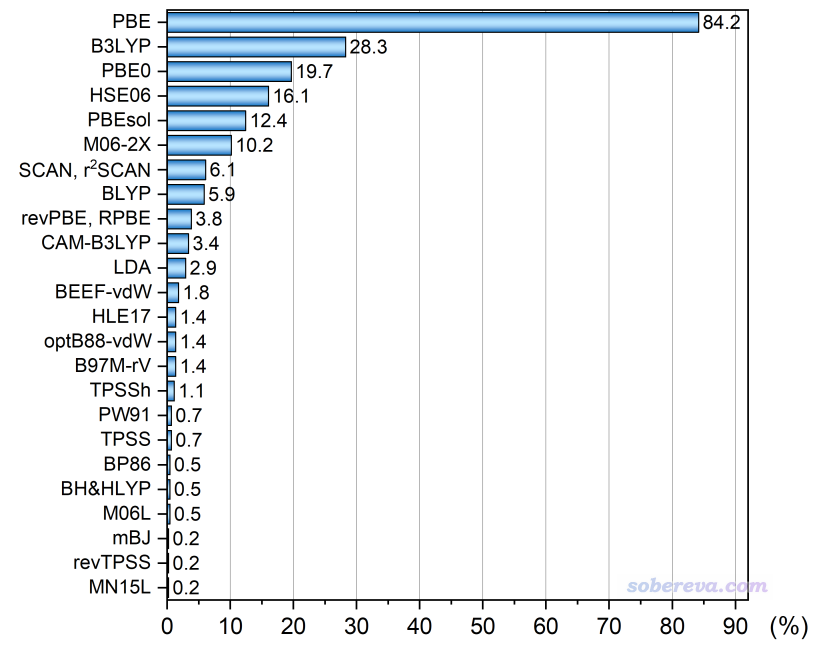
96年提出的PBE至今仍穩居第1的位置,如同B3LYP在量子化學領域的地位,而且和第二名相差更懸殊。PBE能有這樣的地位是必然的,PBE提出年代早、被程序支持得極為廣泛,計算便宜,有豐富的專門為其搞的贗勢,幾何優化和分子動力學目的大多數時候夠用(加色散校正后又拓寬了其普適性),而且在基態能量相關問題方面依然有使用價值而且沒被已流行的其它純泛函甩開特別多(這和B3LYP在量子化學領域的情況截然不同,B3LYP算能量早過時了,很難再發得出去文章,見http://bbs.keinsci.com/thread-12773-1-1.html)。B3LYP在這次投票里得了第2,令我有點意外,大概率是很多人不好好看投票帖子的說明,誤把量子化學研究用的泛函也在此進行投票了。PBE0能排第3不意外,需要一個HF成分適當的雜化泛函做TDDFT/TDDFPT算激發態、算強相關體系的問題時經常用得著。HSE06流行度排得上第4主要來自于其計算帶隙、能帶方面公認很好,以及晶胞參數優化方面表現不錯。PBEsol是優化晶體結構、晶胞參數的好把式,而且還是便宜的純泛函,能排到第5很正常。M06-2X能排第6令我有點意外,一方面必定是有人誤當成量子化學計算的情況來投,另一方面是計算主族晶體/液體相關的化學反應、吸附的相關能量問題必定有一些人在用。SCAN/r2SCAN已經有一定流行度,由于在文獻中出現頻率越來越高,在未來的流行度必定也會逐漸提升,但流行度超越PBE在可預見的未來還不太可能,畢竟對于大量PBE就已經表現得夠用的范疇,作為更貴但沒帶來顯著優勢的meta-GGA的SCAN/r2SCAN不可能顯著侵占這方面的市場。第一性原理領域里用BLYP的人我不很理解是什么心態。revPBE和與之相似的RPBE能有一定流行度在于算化學吸附方面不錯,被不少人用。第一性原理方面的泛函投票中CAM-B3LYP顯得遠不如量子化學領域里來得流行,估計用這個的大部分都是CP2K用戶用來算激發態和UV-Vis譜方面,只占投票的少量群體。算化學吸附很好的BEEF-vdW和算物理吸附很好的optB88-vdW能有一定票數不算意外。純泛函中矮子里拔將軍算帶隙往往可以接受的HLE17在本次投票中獲得了一點流行度,略意外的是算帶隙整體更好些的純泛函mBJ反倒在這次投票中顯得無人問津,可能是前者在CP2K里能直接用而后者不能所致。作為PBE后繼提出來的知名的TPSS流行度那么低有點令我意外,倒也確實實際用處不太大,現在又有了理論上以及實際整體表現得更好的r2SCAN。PW91雖然在文獻里出現得很多,但這次得票率相當低,畢竟實際中有PBE就基本沒有更老的PW91能派上用場的時候。B97M-rV能有少量票數,主要在于算熱力學量方面在純泛函里是表現得較突出的。
3 你最常用的量子化學程序投票
可投程序有29種,投票者共679人。本投票每個人最多選三項,且所投的程序必須占平時全部研究工作的10%以上。按照得票率繪制的圖如下,只顯示了得票前20名的
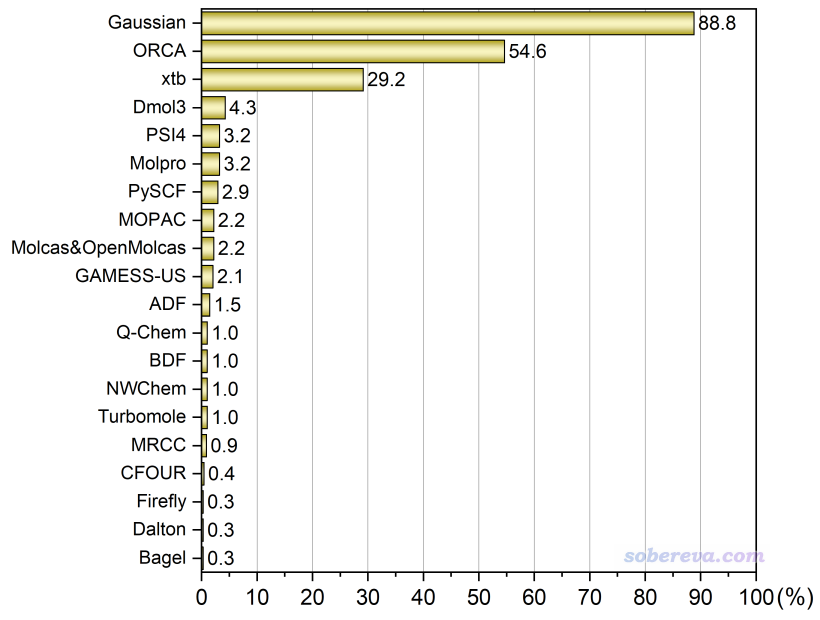
前三位和2021年投票的結果一樣,還是Gaussian > ORCA > xtb,Gaussian依然是約90%的量子化學研究者日常必用的程序,穩穩占據主導位置。而ORCA和xtb的得票率比2021年時都有了約10%增長,這是意料之中的。實際上這三個程序也是我自己最常用的:xtb拿來快速預優化和結合molclus(http://www.keinsci.com/research/molclus.html)做構象搜索的初篩,Gaussian做基于DFT的opt、freq、掃描、IRC等涉及幾何變化的任務以及算一些屬性(NMR、超極化率等),ORCA算高精度單點。這三個程序的流行度遠遠甩開了其它程序,一方面是它們比較容易安裝和使用,一方面各有各的獨特優勢,有被大量使用的剛性原因。而且它們把大部分量子化學計算的應用領域都給覆蓋了,對于日常應用性研究來說其它程序難以有和它們競爭的顯著空間。Dmol3、ADF、Q-Chem、Turbomole這四個商業程序日子愈發不好過。在量化計算方面沒有長處還巨貴的Dmol3的用戶越來越少,從2021年的6.2%已經進一步萎縮到了4.3%,以后肯定還會明顯進一步萎縮。ADF從2021年時候的僅僅2.2%進一步萎縮到了1.5%。Q-Chem從2021年的3.0%萎縮到了1.0%。Turbomole從2021年的1.6%萎縮到了1.0%。以GPU加速為賣點的TeraChem更不幸,2021年時候還有1人投票,今年變成了0人。
4 你最常用的第一性原理程序投票
可投程序有25種,投票者共565人。本投票每個人最多選三項,且所投的程序必須占平時全部研究工作的10%以上。按照得票率繪制的圖如下(0票的沒顯示)
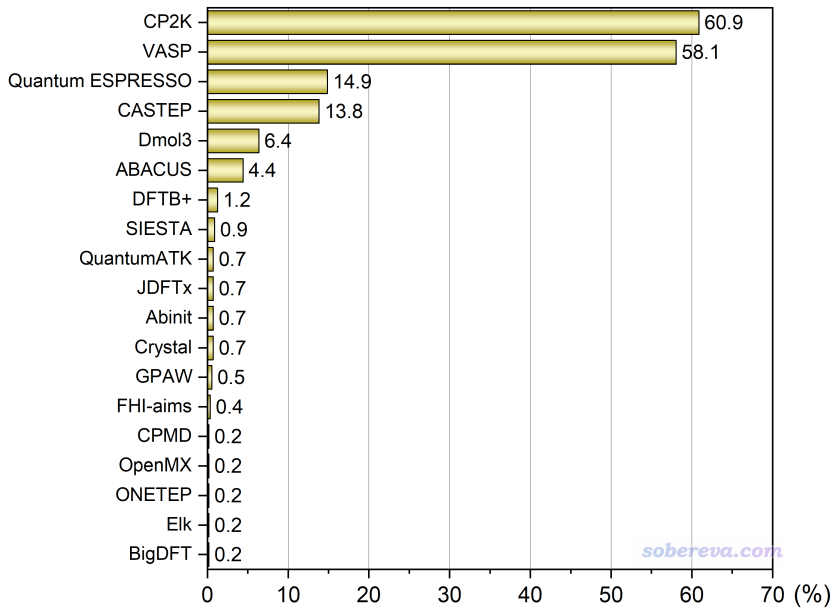
根據這次投票的結果可見,至少在計算化學公社論壇里,CP2K的流行程度已經趕超了VASP。這令我90%程度感到意外,但也有10%程度感覺是在情理之中。由于Multiwfn在2021年開始提供了極其易用的創建CP2K輸入文件的功能(http://www.shanxitv.org/587),我后來又對此功能反復打磨并在Multiwfn中提供了對CP2K繪制DOS、能帶、STM、電子激發、成鍵分析等許多功能,再加上2023年3月、2023年10月和2024年3月開辦了三期北京科音CP2K第一性原理計算培訓班(http://www.keinsci.com/workshop/KFP_content.html)非常全面系統講解了CP2K的使用,無疑令中國的CP2K用戶猛增。但即便我已預料CP2K的得票率肯定會遠高于2021年時候的33.3%,但也沒預料到這次居然能達到60.9%,直接翻了將近一倍,甚至把一直霸占流行度榜首的VASP給擠下去了。由于免費且十分高效的CP2K的用戶還在不斷激增,而且CP2K更新很快,不斷完善和發展新功能,Multiwfn在未來還會給其提供更多的相關分析處理功能,CP2K的位置在以后無疑還會更加牢固。相比之下,VASP的流行度從2021年投票時候的65.8%降到了現在的58.1%。由于現在有非常強大的競爭者CP2K,而且CP2K不具備的一些功能還有免費的Quantum ESPRESSO能用來平替VASP,售價較昂貴且算大體系速度遠不如CP2K的VASP在未來的前景不樂觀。以前很多人一提到第一性原理計算就言必稱VASP,以后就不再是如此了。除了CP2K的流行度猛增外,其它程序的流行度都普遍出現了下降,如CASTEP和Dmol3分別從2021年的19.0%和9.3%下降到了13.8%和6.4%。Wien2k今年更是連一票都沒有,而2021年時還有3票。那些程序流行度百分比減少,一方面是它們的票數大多數確實有一定減少,用戶發現有更理想或免費的程序可用,另一方面原因應當是有很多通過CP2K程序開始入手第一性原理計算的人加入了投票,他們只對CP2K的得票率有貢獻而間接地拉低了其它程序的得票率。
5 你最常用的分子動力學程序投票
可投程序有18種,投票者共551人。本投票每個人最多選三項,且所投的程序必須占平時全部研究工作的10%以上。按照得票率繪制的圖如下
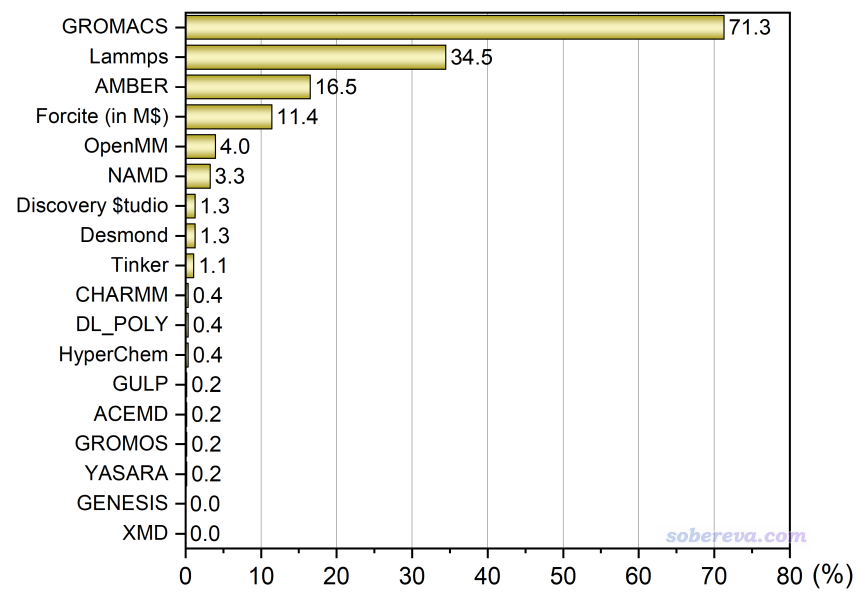
GROMACS依舊是用戶數的龍頭老大,而且流行度從2021年投票時的69.3%還進一步略微提升到了71.3%,得票數大約等于其它所有程序用戶數之和,和曾經的情況一樣。第2、3位依然分別是Lammps和AMBER。Lammps和OpenMM得票率略漲,而AMBER、Forcite和NAMD的流行度都有較多降幅,GULP、DL_POLY和CHARMM更是快跌沒了。
]]>Several tools for constructing three-dimensional structures based on nucleic acid sequences
文/Sobereva@北京科音 2023-Dec-20
之前我在《幾種基于氨基酸序列構建很簡單蛋白質三維結構的工具》(http://www.shanxitv.org/687)中介紹過一些基于氨基酸序列構建簡單蛋白質三維結構的工具,本文將介紹幾種基于核酸序列構建DNA/RNA三維結構的工具,可以用于做分子動力學模擬、分子對接等目的。雖然還有很多其它程序也可以構建,如HyperChem等,但本文提供的這些就已經足夠用了,且都是免費的。這些工具在產生核酸結構時只需要指定一條鏈的序列,從5'端到3'端,對于產生雙鏈結構的情況,另一條鏈的序列總是自動按照規范DNA中標準堿基配對方式自動確定的。這些程序都可以保存成常用的pdb文件格式,并且原子名是規范的。
1 在線工具DNA Sequence to Structure
地址:http://www.scfbio-iitd.res.in/software/drugdesign/bdna.jsp
輸入DNA序列以及DNA結構類型,即可立刻返回產生的pdb結構,例如:
返回的結構用VMD查看:
2 在線工具web.x3dna.org
進入后,選Rebuilding - combination of A-, B-, or C-form DNA models。之后可以輸入DNA序列由幾段構成,比如設了3,點next,若三段內容分別按下面這樣設,那么DNA序列就是AAACCCCGGG,且其中AAA部分是A-DNA形式、CCCC部分是B-DNA形式、GGG部分是C-DNA形式。

提交之后,過一會兒(有可能時間挺長),看到下圖,可以點擊鏈接下載pdb文件
3 AmberTools的NAB
AmberTools程序包可以在http://ambermd.org下載,NAB是AmberTools中的組件,AmberTools裝好后NAB就可以直接用了。最簡單的運行方式為nab test.nab -o test.out,這里test.nab是NAB程序的輸入文件(后綴必須是nab)。NAB就像編譯器一樣會編譯出名為test.out的可執行程序,然后運行./test.out即可使里面的指令生效。
NAB可以用于創建DNA和RNA序列。例如創建一個序列為gcgttaacgc的B-DNA結構,就創建一個文本文件比如叫genDNA.nab,里面寫以下內容
molecule m;
m = fd_helix("abdna","gcgttaacgc","dna" );
putpdb( "sobDNA.pdb", m );
之后運行nab genDNA.nab -o genDNA,當前目錄下就出現了名為genDNA的可執行文件。再輸入./genDNA運行之,當前目錄下就出現了sobDNA.pdb,是我們要的DNA的結構,DNA的骨架順著Z軸。
從上面例子可見fd_helix函數里面跟了三個參數,第一個參數控制產生的核酸類型,第二個參數是序列,第三個參數寫dna就是生成DNA、寫rna就是生成RNA。

4 Gabedit
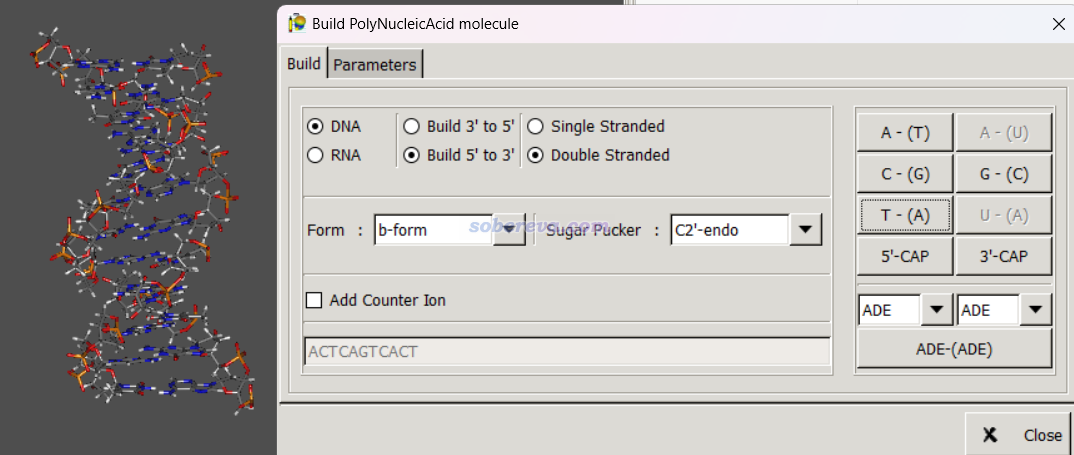
Gabedit是一個免費的可視化程序,可以在http://gabedit.sourceforge.net下載。啟動后點擊菜單欄Geometry - Draw,然后點右鍵選Build - polyNucleic Acid,之后一邊點擊堿基名字的按鈕,三維結構一邊不斷產生,如下圖所示。可見核酸類型和結構形式都可以自己定義。如果選上Add Counter Ion,產生的核酸結構的磷酸基旁邊還會自動加上Na+作為抗衡離子。構建好后,在圖形窗口上點右鍵選Save as,就可以選擇保存成pdb格式。
5 Avogadro
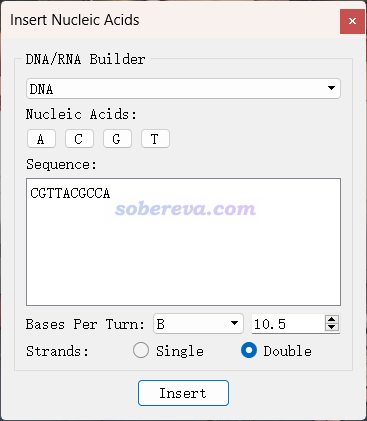
Avogadro可視化程序可以在http://avogadro.cc免費下載。啟動Avogadro后,點擊菜單欄的Build - Insert - DNA/RNA,就蹦出了如下窗口。然后一邊點擊按鈕輸入核酸序列,一邊圖形窗口里就可以看到生成的核酸結構。DNA和RNA,單鏈和雙鏈,結構形式都可以自由選擇。
Several tools for constructing three-dimensional structures of very simple proteins based on amino acid sequences
文/Sobereva@北京科音 2023-Oct-15
經常有人問已知很簡單蛋白質(小肽)的氨基酸序列,怎么得到其三維立體結構,這里就介紹幾種工具。本文并不是對相關程序做完整的收集,介紹的這些已經足夠滿足各種實際情況的需要了。注意本文的范疇和蛋白質結構預測完全不同,那類程序是用于構造有三級結構的較復雜蛋白質用的,本文涉及的工具頂多只牽扯到二級結構。
需要注意的是,只有其中部分程序可以產生原子名符合IUPAC規范的pdb結構文件。僅對于這種情況,pdb文件才可以載入VMD后正常顯示二級結構(至少得骨架重原子名滿足IUPAC規范),以及能夠直接被比如GROMACS的pdb2gmx所處理來產生拓撲文件。
筆者另外寫了篇文章介紹通過輸入序列產生DNA或RNA三維結構的工具,見《幾種基于核酸序列構建三維結構的工具》(http://www.shanxitv.org/692)。
1 ProBuilder
這是個在線程序,網址是https://www.ddl.unimi.it/vegaol/probuilder.htm。用戶只需要輸入氨基酸序列,比如RLCVVPIRLPPLRERT,并且指定要產生的二級結構的phi、psi、omega角度,就可以獲得結構文件。能產生的格式很多,包括符合IUPAC命名規范的pdb文件。此程序產生的結構可以要求帶和不帶側鏈,帶側鏈的情況由于不會自動做結構優化,因此側鏈往往有嚴重重疊,后面介紹的很多程序也都是如此。
2 GaussView
Gaussian的官方界面程序GaussView提供了生物分子片段庫,如下所示。可以選擇位于鏈中間、N端、C端的各種氨基酸殘基片段,在建模窗口點擊一次出現第一個殘基后,再一次一次點擊肽鍵末端,就可以逐漸得到滿足要求的肽鏈。
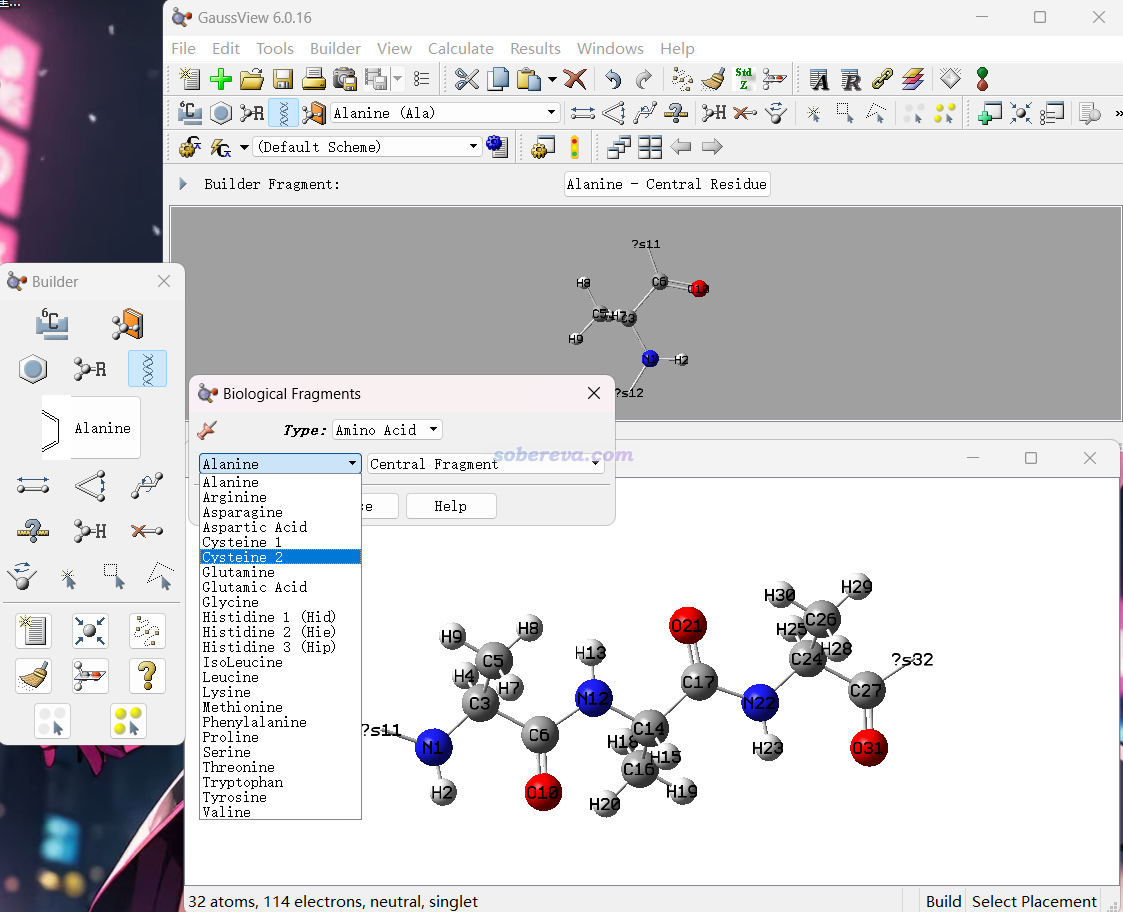
建好后可以保存成結構文件,包括pdb格式。用此程序的優點是可以自行精細修改三維結構,缺點是沒法把一長串序列一下子轉化為三維結構,而且這么保存的pdb文件里的原子名只是元素名而不是滿足IUPAC規范的名字,里面連殘基名都沒有,而且也沒法像ProBuilder那樣直接設置對應特定二級結構的phi和psi角度(得手動一個一個調)。
3 Avogadro
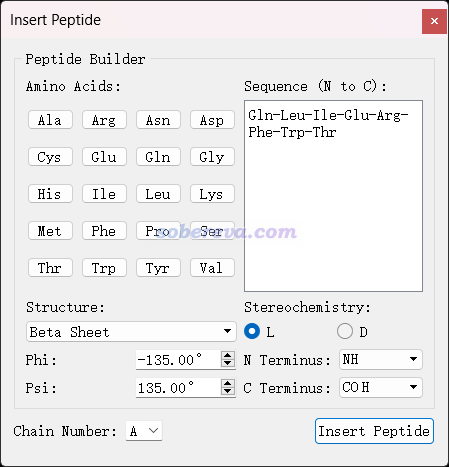
免費的可視化程序Avogadro(http://avogadro.cc)的Build - Insert - Peptide界面可以構建有特定二級結構、特定序列的小肽的三維結構,界面如下所示。可以保存出許多格式,保存成pdb的話原子名和殘基名都是符合IUPAC規范的。此程序還自己支持GAFF、MMFF94等力場做幾何優化,可以用于把建模后側鏈的不合理接觸消除掉。
4 gabedit
啟動免費的可視化程序gabedit(http://gabedit.sourceforge.net)后,點菜單欄的Geometry - Draw,在新窗口里點右鍵,選Build - PolyPeptide,就可以看到構建多肽的界面,如下所示,也可以類似于Avogadro去產生符合特定二級結構的指定序列的小肽。每點擊一次氨基酸的按鈕在圖形窗口里就會長出來相應的殘基。之后點右鍵選save as,就可以保存成各種格式,包括滿足IUPAC原子名和殘基名規范的pdb格式。
5 AmberTools中的leap
知名的AmberTools(http://ambermd.org)程序里的leap可以用于根據氨基酸序列產生線型小肽的三維結構并保存成符合IUPAC命名規范的pdb文件。
參考手冊或《Amber14安裝方法》(http://www.shanxitv.org/263)安裝AmberTools后,在命令行窗口輸入諸如tleap -f leaprc.protein.ff14SB即可啟動純文本界面的leap(tleap)且同時載入AMBER14SB力場相關的氨基酸的庫文件。在里面可以輸入比如如下命令定義一個序列,其中殘基的N結尾和C開頭分別代表N端和C端殘基
TC5b = sequence { NASN LEU TYR ILE CGLN }
之后再運行以下命令就可以把序列以三維結構保存成/sob目錄下的TC5b_linear.pdb了
savepdb TC5b /sob/TC5b_linear.pdb
6 PeptideBuilder
PeptideBuilder是個基于Python的輕量級構建小肽的庫,網址是https://github.com/clauswilke/PeptideBuilder,具體介紹見原文PeerJ, 1, e80 (2013)。
在Linux下聯網狀態運行pip install PeptideBuilder即可安裝。之后可以基于PeptideBuilder寫Python腳本來構造小肽結構,可以指定psi和phi角度、有哪些殘基等。此程序只產生重原子坐標,沒有氫。產生的pdb文件符合IUPAC命名規范。
以下是個例子,比如保存為createQ6.py,之后運行python createQ6.py,就可以在當前目錄下得到含有6個谷氨酰胺的yohane.pdb文件。
from PeptideBuilder import Geometry
import PeptideBuilder
geo = Geometry.geometry("Q")
geo.phi = -60
geo.psi_im1 = -40
structure = PeptideBuilder.initialize_res(geo)
for i in range(5):
PeptideBuilder.add_residue(structure, geo)
PeptideBuilder.add_terminal_OXT(structure)
import Bio.PDB
out = Bio.PDB.PDBIO()
out.set_structure(structure)
out.save("yohane.pdb")
有人基于PeptideBuilder做了擴展寫了額外Python程序,能生成具有指定序列在N端加上Fmoc或ACE(乙酰)封閉、在C端加上NME(甲胺基)封閉的pdb文件。見《生成任意序列的封端短肽pdb的腳本CappedPeptideBuilder.py》(http://bbs.keinsci.com/thread-30278-1-1.html)。一個簡單例子:先把PeptideBuilder裝上,然后把CappedPeptideBuilder.py放在當前目錄下,再運行python CappedPeptideBuilder.py -s KEYIN -p test,此時當前目錄下就出現了test目錄,其中ACE_KEYIN.pdb就是N端加了乙酰、C端加了甲氨基的序列為KEYIN的小肽結構了(沒有氫)。
7 Tinker
動力學模擬程序Tinker有根據序列建立蛋白質三維結構的命令protein,參見計算化學公社論壇的帖子:http://bbs.keinsci.com/forum.php?mod=redirect&goto=findpost&ptid=11478&pid=79011&fromuid=1
]]>Theoretical design of a novel dual-motor supramolecular system based on cyclo[18]carbon
文/Sobereva@北京科音 2023-Aug-14
1 前言
北京科音自然科學研究中心(www.keinsci.com)的盧天和江蘇科技大學的劉澤玉等人近期設計了由18碳環(cyclo[18]carbon, C18)和具有兩個大環的分子(OPP)構成的非常新穎的雙馬達超分子體系,并做了詳細的分子動力學特征的研究,相關工作已發表在知名的Chemical Communications通訊刊物上,文章信息如下,歡迎閱讀和引用:
Zeyu Liu,* Xia Wang, Tian Lu,* et al., Theoretical design of a dual-motor nanorotator composed of all-carboatomic cyclo[18]carbon and a figure-of-eight carbon hoop, Chem. Commun., 59, 9770 (2023) DOI: 10.1039/D3CC02262E
https://pubs.rsc.org/en/content/articlelanding/2023/CC/D3CC02262E
鏈接:https://pan.baidu.com/s/1H7AcSnDqbjBOE2ajFk-LXA?pwd=tnzv
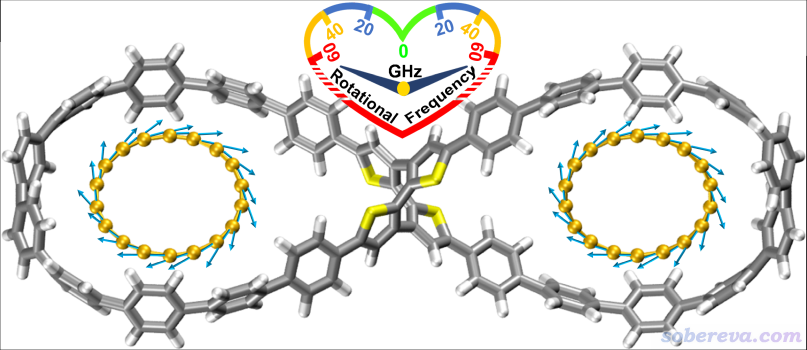
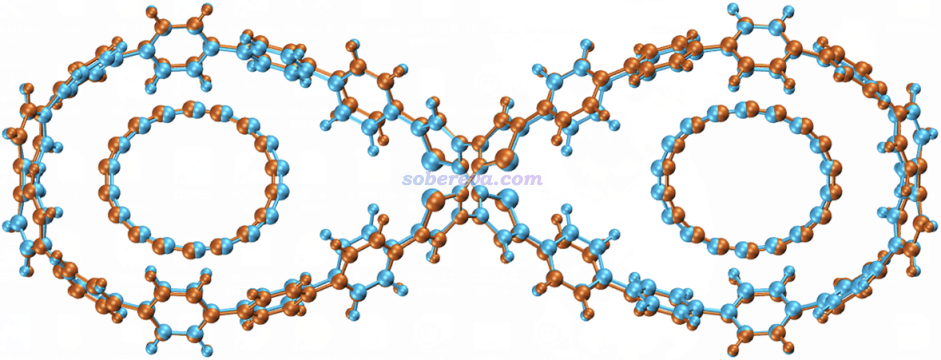
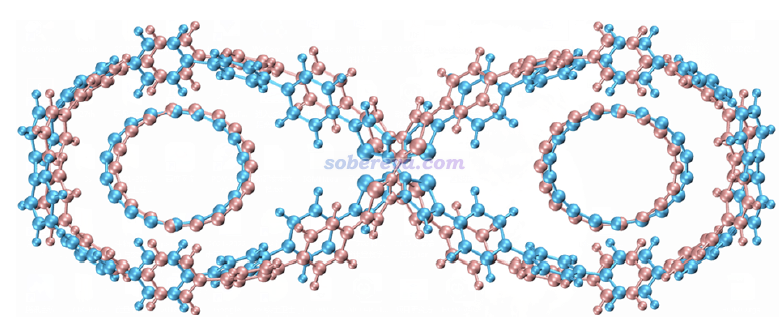
下面將對此文的主要研究內容和思想進行深入淺出的介紹,以有助于讀者更好地理解文章內容。下圖是被研究的雙馬達超分子體系的結構圖和運動方式示意
值得一提的是,同作者之前還深入細致地考察了上文研究的OPP對18碳環的吸附和釋放的動力學過程及相互作用本質,已發表于Phys. Chem. Chem. Phys., 25, 16707 (2023) DOI: 10.1039/d3cp01896b,并在《8字形雙環分子對18碳環的獨特吸附行為的量子化學、波函數分析與分子動力學研究》(http://www.shanxitv.org/674)中做了詳細介紹,推薦閱讀。同作者之前還對18碳環及衍生物的各方面性質還做了非常廣泛的研究,相關工作匯總見http://www.shanxitv.org/carbon_ring.html。
2 設計思想
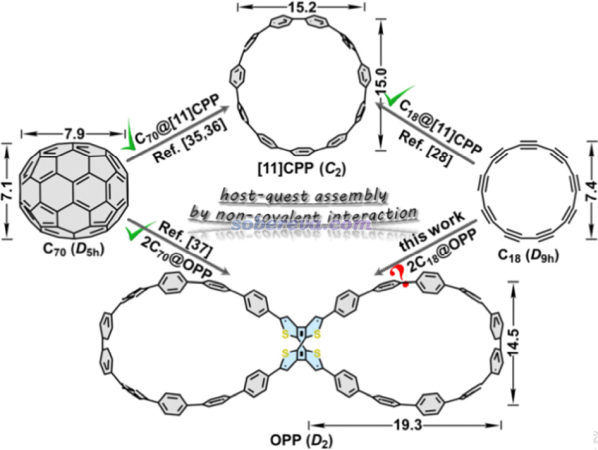
18碳環這個奇妙的分子雖然在半個多世紀以前就被理論預測,但直到2019年才首次在凝聚相實驗觀測到,并迅速引發了巨大關注。它的直徑和C60富勒烯很相似,對比見下圖
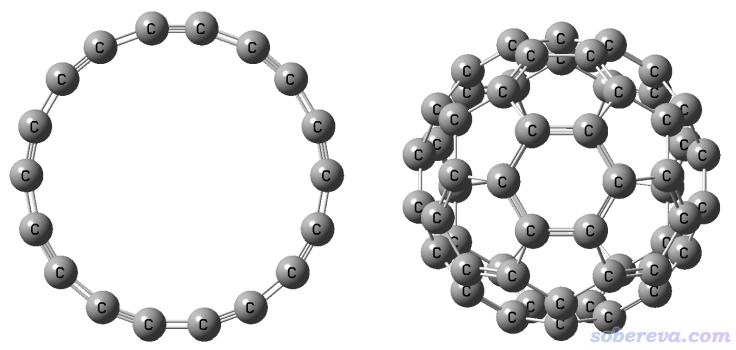
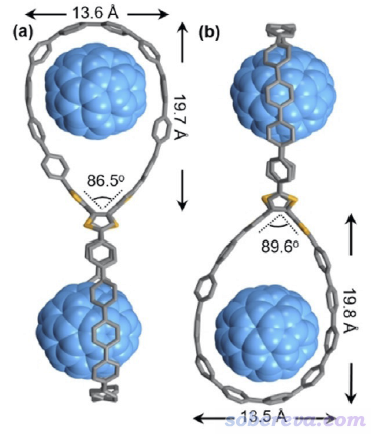
具有較大雙環結構的OPP分子在Angew. Chem., Int. Ed., 61, e202113334 (2022)中被首次合成出來,實驗上得到了它帶有C60和C70富勒烯的晶體,C60@OPP的晶體結構如下所示,可見C60被嵌入在了大環里面
由以上結構特征可以想到兩個C18也可以分別內嵌到OPP的兩個大環中,成為2C18@OPP。倘若每個C18在OPP的大環里能夠由于熱的驅動而較容易地發生轉動,自然就成了雙馬達超分子體系。這樣的體系在之前的文章中是沒有報道的,此體系或類似物在未來有望成為構造復雜分子機器的關鍵組成部分。本文介紹的Chem. Commun.這篇文章的目的就在于通過量子化學和分子動力學模擬來證實OPP與C18復合作為雙馬達體系的可能性并考察其特點。
3 基于量子化學的能量角度的研究
文中首先使用量子化學方法從能量角度對C18@OPP和2C18@OPP進行了研究。首先使用Gaussian程序通過ωB97XD泛函優化了復合物結構并做了振動分析。2C18@OPP達到了260個原子,為了節約時間,對占體系大部分原子的OPP部分用了6-31G*基組,而關鍵的C18部分用了更好的6-311G*基組(在http://www.shanxitv.org/584中也指出6-31G*無法合理描述C18)。對相應單體也在對應的級別做了優化和振動分析。之后通過ORCA程序使用ωB97X-V/def2-TZVP級別結合counterpoise校正計算了它們的結合能(做法可參考《在ORCA中做counterpoise校正并計算分子間結合能的例子》http://www.shanxitv.org/542),發現C18 + OPP以及C18 + C18@OPP的結合能分別為-18.4和-18.5 kcal/mol,一方面說明C18與OPP有較強的內在結合能力,另一方面說明C18@OPP的已進入的一個C18幾乎不影響OPP對第二個C18的結合能力。之后,文中通過《使用Shermo結合量子化學程序方便地計算分子的各種熱力學數據》(http://www.shanxitv.org/552)介紹的Shermo程序計算了C18、OPP、C18@OPP和2C18@OPP常溫下自由能熱校正量,并進而得到了常溫下的C18 + OPP和C18 + C18@OPP的結合自由能,分別為-6.0和-4.0 kcal/mol,明顯為負值說明C18的進入是熱力學上可自發的,其大小明顯小于結合能是來自于分子間復合帶來的熵罰效應。
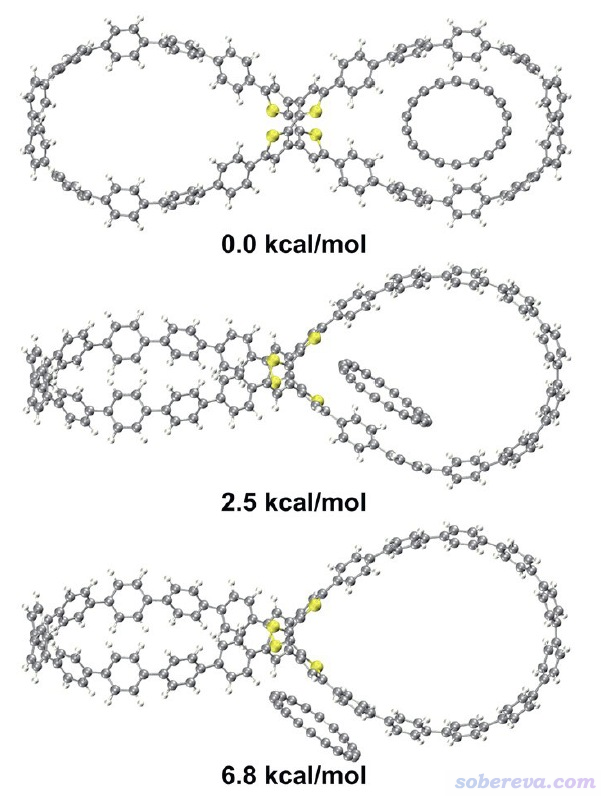
審稿人問及C18是否有可能與OPP存在其它結合方式。為了說明這一點,此文的補充材料里給出了優化出的其它兩個C18與OPP復合物的極小點結構,如下所示,相對于C18平行地嵌入在OPP大環內的結構的能量差也在下圖給出了。可見其它兩種結構都是能量更高、明顯更不穩定的。在《8字形雙環分子對18碳環的獨特吸附行為的量子化學、波函數分析與分子動力學研究》(http://www.shanxitv.org/674)介紹的PCCP文章中實際上也已經通過分子動力學模擬證明了C18沒有其它的能夠與OPP穩定結合的方式。
文中進一步研究了C18的旋轉勢壘。對C18@OPP和2C18@OPP優化的C18旋轉的過渡態結構如下(a)所示,可見虛頻數值非常小,暗示旋轉勢壘肯定很低。圖中的箭頭體現了虛頻方向,可見明顯對應的是C18的整體旋轉。此圖是按照《在VMD中繪制Gaussian計算的分子振動矢量的方法》(http://www.shanxitv.org/567)介紹的方式繪制的。
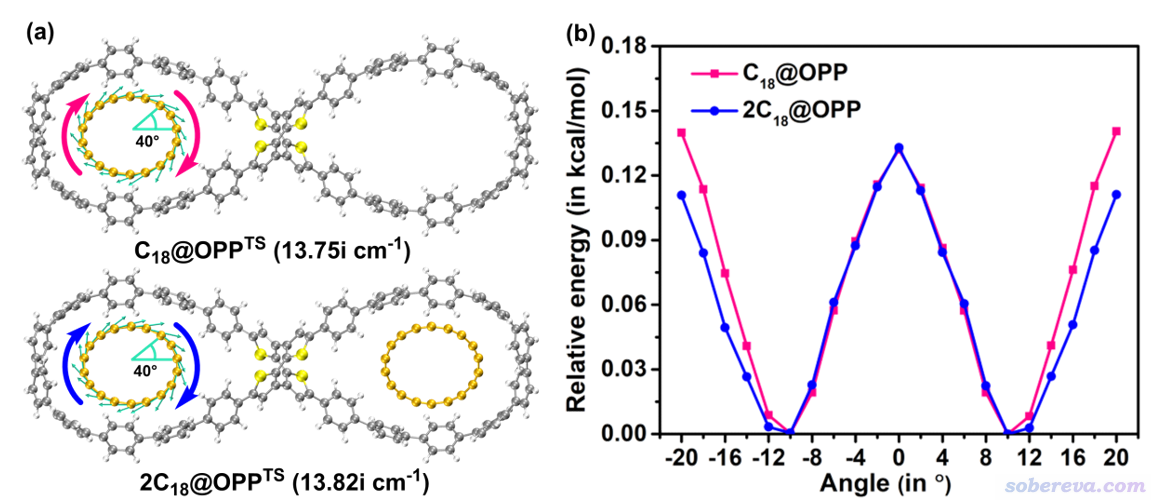
進一步,文中對C18在OPP大環中的旋轉進行了掃描(計算級別同幾何優化),如上圖(b)所示,其中橫坐標是旋轉角度,0處為過渡態結構。可見旋轉勢壘非常低,只有0.13 kcal/mol,這體現C18在OPP大環中的旋轉必然很容易靠熱運動來驅動。上圖橫坐標范圍對應一個旋轉周期,是40度,這也正對應于18碳環的極小點結構是D9h的特征。圖中看上去每20度有一個極大點,這是因為18碳環是18個原子構成的環狀體系,如果忽視其長-短鍵交替特征的話,就相當于20度一個旋轉周期。
4 分子動力學模擬C18在OPP中的運動行為
分子動力學模擬研究是本文最關鍵的部分,模擬出的動力學行為是C18與OPP復合物能否作為分子馬達的決定性證據。此文使用GROMACS程序通過經典力場進行動力學模擬,使用靈活的sobtop程序(http://www.shanxitv.org/soft/Sobtop)構建拓撲文件,主要基于GAFF力場,部分參數利用OPP的Hessian矩陣由sobtop產生,相關細節在《8字形雙環分子對18碳環的獨特吸附行為的量子化學、波函數分析與分子動力學研究》(http://www.shanxitv.org/674)里有描述,這里就不多提了。
2C18@OPP處于300 K的平衡狀態時的200 ps動畫如下所示(是在文章的補充材料里提供的)。為了能讓C18的旋轉特征看得清楚,其中一個原子以紅色來標記。由動畫可見,的確C18在OPP中能夠非常順利、自如地轉動起來,充分證實了此文提出的雙馬達超分子體系的設想!
http://www.shanxitv.org/attach/684/2C18_OPP_rotator.mp4 (點擊查看動畫)
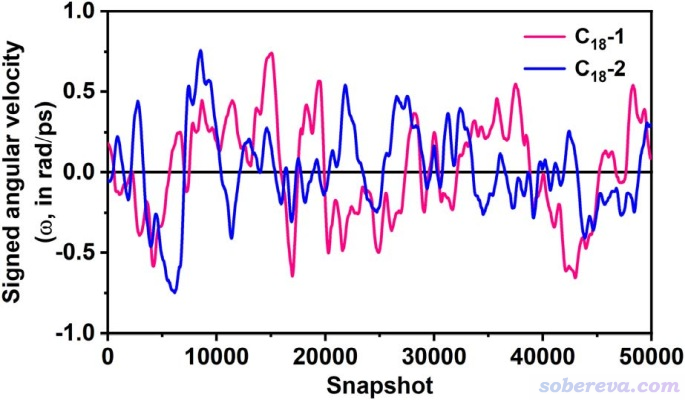
需要注意的是,由于原子間頻繁碰撞導致的動能交換,單靠熱運動驅動的C18在OPP中的旋轉并非始終是單向的。300 K下模擬的50000幀(0.2 ps保存一幀,故相當于10 ns)中的2C18@OPP中兩個C18的旋轉角速度如下所示(數據已通過Savitzky-Golay算法利用相鄰1000個數據點做了平滑化處理以消除噪音)。由圖可見C18的含符號角速度不斷發生變化,時正時負,時大時小,因此C18的旋轉不能視為是連貫、無摩擦的。從圖上兩條曲線也可以看到2C18@OPP的兩個C18彼此間的運動并沒有什么相關性。由于它們離得遠,自然也不會有什么明顯的直接的耦合或者藉由OPP的結構產生的間接耦合。
5 分子動力學模擬C18在OPP中轉動的統計行為
文中在50、100、200、300、400 K的熱浴下都做了100 ns的分子動力學模擬,并通過自寫的軌跡分析程序考察了C18在OPP中轉動的統計行為,結果如下表所示。在溫度不是很低情況的模擬過程中,偶爾C18會傾斜地倚靠在OPP的內側,此時的體系明顯不算是轉子。這種情況的幀數占總模擬幀數的百分比是下表的p_out,這些幀不納入C18轉動行為的統計。可以看到從200 K開始,隨著溫度上升,處于這種亞穩狀態的比例隨之上升。
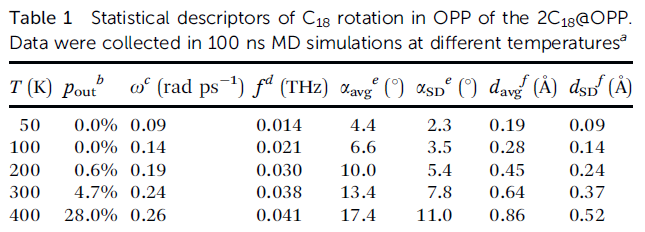
上表中ω是平均無符號轉動角速度,可見隨著溫度越高、體系中原子的平均動能越大,C18平均旋轉速度也隨之上升。但是300 K變化到400 K過程中平均旋轉速度增大甚微,這主要在于400 K的時候C18在OPP中的狀態已經很不穩定了,過強的熱運動很大程度影響了C18轉動的有序性。上表中f=ω/(2π)是換算出來的轉動頻率,2C18@OPP屬于亞THz范圍的超快轉子。
上表中αavg、αSD分別是C18環平面與OPP大環平面之間在模擬過程中的夾角的平均值和標準偏差,d_avg和d_SD分別是C18環中心與OPP環中心之間在模擬過程中的距離的平均值和標準偏差。從這些指標來看,隨著模擬溫度提升得越高,2C18@OPP偏離其極小點結構(α和d都近乎為0)的程度越高,越缺乏理想轉子特征。
下圖展現了VMD繪制的2C18@OPP在100 ns動力學過程中的軌跡疊加圖,每1 ns繪制一次,根據幀號從前到后按照紅-白-藍著色。可見在100 K的時候由于熱運動弱,體系結構基本上就是在極小點結構附近很小范圍波動。到了更高的200 K后OPP的運動幅度以及C18的運動范圍都顯著增加了。在300 K的時候結構波動更大,還明顯看到C18都偶爾側貼在OPP大環內側了。到了400 K的時候C18在OPP大環里的運動其實已經很大程度算是無序了,甚至仔細看軌跡都會發現C18在大環內出現了整體翻轉。可以預期如果溫度明顯更高的話,C18甚至就能從OPP的大環中跑出去了,比如臨時性跑到OPP外側乃至飛走。
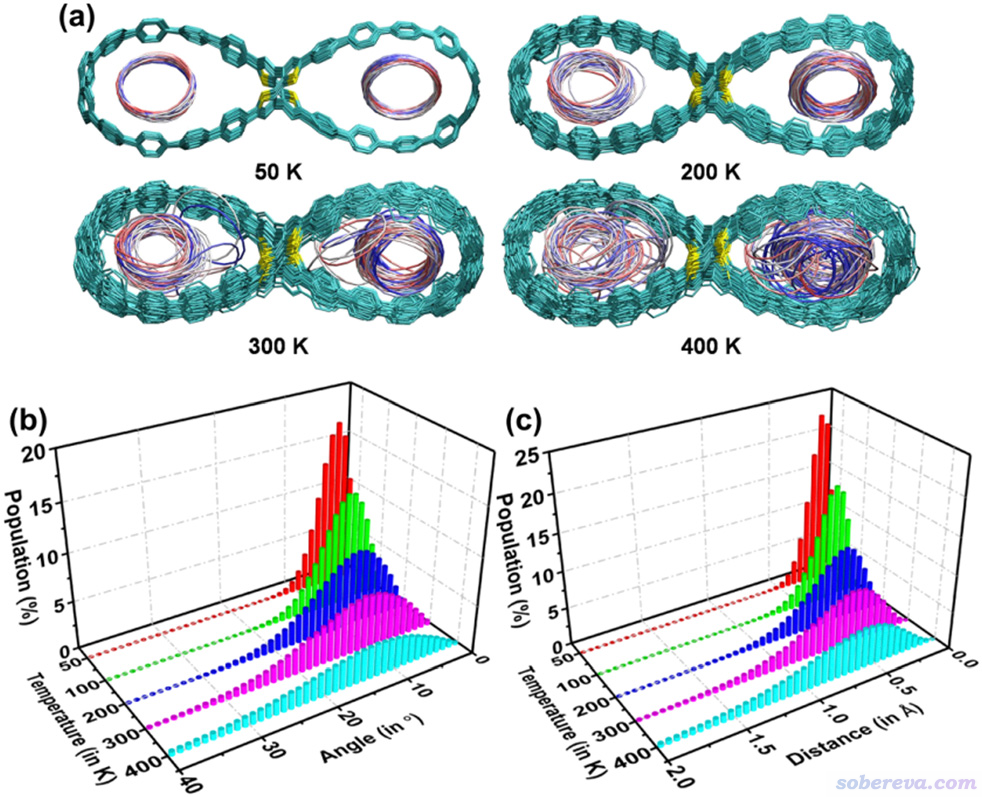
上圖的(b)和(c)對不同溫度下模擬的C18在OPP中的結構狀態做了統計分析,包括C18與OPP大環間的夾角以及中心距離,可見這兩個衡量C18在OPP中結構狀態的參數的分布都是隨著溫度增加而顯著變寬,也即在模擬過程中C18的朝向和位置的波動程度愈發增大,這和軌跡疊加圖展現的信息是一致的。
6 總結
本文介紹了近期發表于Chem. Commun., 59, 9770 (2023)的理論設計的雙轉子超分子復合物結構,此工作從能量和動力學角度對體系進行了全面的研究,充分證明了此體系作為超快納米轉子的能力,并對其轉子性能以及溫度依賴性做了系統的考察。由于OPP和C18都已經被合成出來,因此此體系或者其變體有望成為有實際價值的分子機器的組成部分,本文的研究思想和發現對于納米轉子類體系在未來的探索也有顯著的啟示作用。
]]>Distinguishing tasks and theoretical methods in computational chemistry
文/Sobereva@北京科音
First release: 2023-Aug-5 Last update: 2024-Dec-9
0 前言
在網上答疑時,偶爾看到有初學者搞不清楚任務類型和理論方法,比如今天有人在思想家公社3號群問“md,aimd和qmmm的區別是啥啊?什么需求下會用到這三種呢?”,這三個詞明顯都不是一個層面的東西。此文就把計算化學中的任務類型和理論方法的關系明確一下,簡明扼要地介紹一下相關基本概念,做一個科普,以令計算化學零基礎者一次性搞清楚它們的關系。更多的計算化學的總覽性的知識在北京科音初級量子化學培訓班(http://www.keinsci.com/workshop/KEQC_content.html)里有介紹,此培訓也是從零開始入門量子化學研究的極好方式。
1 任務類型
有N個原子的非線型的體系有3N-6個內坐標描述原子間相對位置關系,在Born-Oppenheimer近似下體系的能量是依賴于內坐標的,也即能量是個3N-6維的函數,這被稱為勢能面(potential energy surface, PES)。計算化學領域有很多常見的任務(task)都是基于勢能面做的,即有了勢能面信息(能夠求得勢能面上任意位置的能量及其導數)就能做這些任務。下面羅列一下常見的這種類型的任務:
? 優化極小點:平時說的幾何優化(geometry optimization)一般也是指這個。此任務從一個給定的初猜結構開始,根據特定算法去尋找與之最近的勢能面上極小點的精確位置。在分子動力學程序如GROMACS里這種任務也被叫做能量極小化(energy minimization, em),只不過實際目的不一樣,em的目的主要是在動力學模擬之前釋放體系中可能存在的較大斥力(自行構建的初始模型里往往有原子間距離太近、斥力太大),免得動力學模擬一開始由于過大的原子加速度造成過大的速度而導致動力學模擬異常或崩潰。
? 優化過渡態:從一個給定的初猜結構開始,根據特定算法去尋找與之最近的勢能面上的一階鞍點的精確位置。過渡態可以視為反應過程中最有代表性的一個結構,可以由此判斷或驗證反應機理,利用它和相鄰極小點的能量求差可以得到反應勢壘,對于討論反應難易有關鍵意義,見《談談如何通過勢壘判斷反應是否容易發生》(http://www.shanxitv.org/506)。優化過渡態的算法介紹見《過渡態、反應路徑的計算方法及相關問題》(http://www.shanxitv.org/44)。
? 產生反應路徑:用于把基元反應對應的勢能面上兩個相鄰極小點之間最容易相互轉變的路徑產生,也相當于得到了一個軌跡并可以觀看對應的結構變化過程,過渡態是此路徑上能量最高點。在質量權重坐標下產生的反應路徑稱為IRC(intrinsic reaction coordinate),不考慮質量權重時產生的一般稱為MEP(minimum energy path)。具體算法很多,見《過渡態、反應路徑的計算方法及相關問題》(http://www.shanxitv.org/44)。反應路徑可認為是實際化學反應過程最有代表性的路徑,自然對于理解反應機理有重要意義,還可以用Multiwfn對反應路徑上各個點做波函數分析考察反應過程中電子結構的變化以獲得更深入的信息,例如《通過鍵級曲線和ELF/LOL/RDG等值面動畫研究化學反應過程》(http://www.shanxitv.org/200)。
? 振動分析:通常是在勢能面上的駐點(所有原子受力都為0的點)做的,用于得到相應結構下的振動頻率,可以用來計算熱力學量,公式看《使用Shermo結合量子化學程序方便地計算分子的各種熱力學數據》(http://www.shanxitv.org/552)介紹的Shermo程序手冊的附錄部分,還可以用來得到振動能級、振動波函數、檢驗幾何優化的準確性(根據虛頻判斷)、繪制振動光譜(參看《使用Multiwfn繪制紅外、拉曼、UV-Vis、ECD、VCD和ROA光譜圖》http://www.shanxitv.org/224)。
? 分子動力學(molecular dynamics, MD):上面的任務都是“靜態”的任務,即不含時間這個維度。而分子動力學則引入了時間這個維度,可以模擬體系狀態隨時間的變化,能研究的問題與那些靜態的任務有極大的互補性,在北京科音分子動力學與GROMACS培訓班(http://www.keinsci.com/workshop/KGMX_content.html)里面有全面的介紹。分子動力學模擬過程相當于體系在勢能面上不斷運動,也相當于是對勢能面的一種采樣方式。雖然其名字叫分子動力學,但研究對象并不限于分子,比如無機固體、金屬團簇的動力學模擬也可以叫分子動力學。最常見的分子動力學的實現形式是BOMD(結合量子化學方法時另有CPMD、ADMP等),也相當于根據原子的位置、速度和受力按照經典牛頓運動方程演化原子的坐標和速度。還有其它一些特殊的動力學形式,如朗之萬動力學、耗散粒子動力學等,如今用得很有限。
? 蒙特卡羅:和分子動力學并列的另一種常見的對勢能面采樣的方法,適用場合相對更少,主要是在多孔材料吸附小分子、計算氣液共存曲線等問題上用得較多。不需要像MD那樣計算受力和速度信息,也沒有明確的時間的概念、無法像MD那樣嚴格地考察含時演化。
? 構型/構象搜索:勢能面上往往有很多極小點,能量最低的那個是全局最小點,可以視為體系最穩定的構型或構象對應的結構,其它的極小點對應亞穩的構型/構象。前面說的幾何優化只能收斂到與初猜結構最近的極小點,顯然這未必是最小點。如果想確保得到最小點(全局優化,global optimization),或者能量最低的一批構型/構象,就需要做構型/構象搜索,方法很多,比如免費的molclus(http://www.keinsci.com/research/molclus.html)就是很常用的實現工具。
還有一大類任務統稱為波函數分析(wavefunction analysis)。量子化學或第一性原理計算會產生電子波函數,根據量子力學原理,波函數蘊含了體系當中一切信息。波函數分析是各種對電子波函數及衍生性質分析的方法的統稱,它能夠將電子波函數這個黑盒子打開,從而提取非常豐富、極為重要的化學上感興趣的信息。波函數分析是量子化學研究當中的關鍵組成,在研究化學體系的電子結構特征(如化學鍵的本質和強度、軌道相互作用、電荷分布、電子定域/離域特征、芳香性)、反應活性/位點/機理、分子間和分子內弱相互作用、電子激發、分子性質(如穩定性、密度、毒性等)、體系對外場的響應(如極化率)等眾多方面有極其重要的價值,是應用性量子化學研究絕對離不開的。文獻中常見的Atoms-in-molecules (AIM)、Nature bond orbital (NBO)、前線軌道理論、概念密度泛函理論(福井函數、雙描述符、軟度/硬度、電負性等)、鍵級分析、原子電荷與布居分析、軌道成分分析、態密度(DOS)、電子定域化函數(ELF)分析、靜電勢/范德華勢分析、定量分子表面分析、電子密度差分析、IRI/IGMH/RDG、NICS、空穴-電子分析、sobEDA能量分解等等耳熟能詳的方法全都是波函數分析中的組成部分。Multiwfn(http://www.shanxitv.org/multiwfn)是波函數分析方面最強大的程序,相關信息見《Multiwfn FAQ》(http://www.shanxitv.org/452)。通過量子化學波函數分析與Multiwfn程序培訓班(http://www.keinsci.com/WFN)可以最完整、全面、系統、深入地學習各種波函數分析知識和Multiwfn等波函數分析程序的使用。
2 理論方法
上一節介紹的那些任務在進行過程中,至少需要計算體系在不同結構下的能量。有的還需要計算受力(勢能面對核坐標一階導數矢量,或者說梯度,的負矢量),如幾何優化、分子動力學。有的還需要計算能量對核坐標的更高階導數,比如振動分析至少需要算二階導數(Hessian矩陣由之構成)。怎么獲得各種任務中涉及的能量及其對核坐標的導數,就是理論方法層面的問題了。下面簡要列舉一些常見的理論方法:
? 分子力場(molecular forcefield):也稱為經典力場(classical forcefield)或分子力學(molecular mechanics, MM),或者經驗勢函數等等。雖然通常帶著“分子”倆字,但實際中不限于用于分子體系。這類方法一般使用簡單的模型描述體系(通常一個原子作為一個粒子,電子與原子核不分開考慮),并用形式簡單的數學函數(勢函數)描述原子間相互作用。例如計算原子間靜電相互作用時,分子力場普遍是給每個原子核位置分配一個點電荷(數值等于原子電荷),然后基于庫侖公式計算。由于分子力場的形式簡單,因此計算耗時極低。分子力場的一個關鍵的局限性是絕大多數分子力場都無法描述化學反應,因為成鍵關系在計算從始至終是固定不變的,是一開始就定義好的。描述化學反應問題主流的是后面提及的量子化學類型的方法,或者反應力場(遠比普通分子力場要貴、支持的程序要少)。分子力場另一個關鍵局限性是依賴于大量參數,一方面影響模擬精度,一方面決定能描述的體系,尋找和構建合適的參數往往不是易事。
? 機器學習勢(machine learning potential):基本思想是通過機器學習的思想構造依賴于原子坐標的分子描述符(如距離矩陣、能量矩陣等)與能量之間的抽象關系,這種關系比上述傳統的分子力場用的勢函數形式明顯更為復雜。
以下提及方法都是量子化學(quantum chemistry, QC)范疇的,也可以叫基于量子力學(quantum mechanics, QM)的方法。
? 密度泛函理論(DFT):是目前在量子化學、第一性原理計算領域用得最普遍的理論方法,因為其性價比非常高,交換-相關泛函(影響DFT計算精度的決定性因素)選擇得當的話可以得到很不錯的結果,足夠滿足絕大多數研究需要,而且精度顯著強于分子力場(除非力場是對某類體系專門訓練得特別精妙的力場),普適性強得多得多,但耗時高于分子力場N個數量級,體系越大N越大。B3LYP、ωB97XD、PBE0、TPSS等等都是常見的交換-相關泛函,各種交換-相關泛函的流行程度見《2024年計算化學公社舉辦的計算化學程序和DFT泛函的流行程度投票結果》(http://www.shanxitv.org/706)中的得票情況,泛函的選用建議見《簡談量子化學計算中DFT泛函的選擇》(http://www.shanxitv.org/272)。很多泛函如B3LYP描述色散作用糟糕或完全失敗,導致這些泛函不適合研究弱相互作用,但可以通過加上色散校正很好地解決,參考《談談“計算時是否需要加DFT-D3色散校正?” 》(http://www.shanxitv.org/413)和《DFT-D色散校正的使用》(http://www.shanxitv.org/210)。值得一提的是,DFT應用到實際問題中實際上分為Kohn-Sham DFT(KS-DFT)和orbital free DFT兩種形式,前者是絕對的主流,計算過程牽扯到軌道波函數,本文以及大家平時說的DFT計算都是用的KS-DFT形式;而后者非主流,不牽扯到軌道,應用的局限性非常大,只有很少數程序支持。
? Hartree-Fock(HF):在DFT興起之前用得很普遍,如今已經完全過時。耗時不比DFT顯著更低(DFT計算時利用RI技術時反倒還可以明顯更快),而精度差得多。
? 后HF:是一大類方法的統稱,如CCSD(T)、MP2、CISD等。HF方法精度爛在于同時沒考慮到動態相關和靜態相關。后HF在HF基礎上額外把動態相關在一定程度上考慮了進來,但耗時也高了很多。動態相關、靜態相關的相關概念很有學問,在北京科音中級量子化學培訓班(http://www.keinsci.com/workshop/KBQC_content.html)里有詳細講授,這里就不多提了。
? MCSCF:主要彌補HF缺乏對靜態相關的考慮。但由于幾乎沒有或很少考慮動態相關,所以結果也說不上好。MCSCF最常見的實現是CASSCF。
? 多參考方法:在MCSCF基礎上進一步把動態相關考慮進來,精度整體很好,普適性很強,但使用相對復雜且昂貴。典型的實現如CASPT2、NEVPT2、MRCI。
? 半經驗:一大類方法的統稱,都是對HF的簡化以巨幅降低耗時,耗時只是HF的微小零頭,整體精度也有不小降低,而且引入了依賴于元素的參數而只能用于有限的元素。典型的如AM1、PM3、PM6。一些較復雜的機器學習勢的耗時已經追平了半經驗。
? GFN-xTB:相當于納入了一定DFT思想的半經驗級別的方法,有不同版本,其中較常用的GFN1-xTB和GFN2-xTB耗時和半經驗相仿佛,而整體精度和可靠性>=主流的半經驗方法,但跟DFT比還有很大差距。GFN-xTB從2017年開始發展,和歷史更早的DFTB有極大的共性。
前面介紹的HF、后HF、MCSCF、多參考方法里面都完全沒有引入經驗參數(極個別的除外,諸如CASPT2可以涉及shift參數),計算中的參數只依賴于物理常數,故它們被稱為“從頭算(Ab initio)”類型的方法。分子力場、半經驗、GFN-xTB由于引入了大量經驗參數,因此明顯不屬于從頭算。DFT算不算從頭算模棱兩可。如今尚未找到的理論上嚴格的交換-相關泛函是不含任何參數的,但如今只有近似的交換-相關泛函被提出,其中雖包含經驗參數,但整體相對較少,因此爭論DFT是否屬于從頭算沒意思,只是個說法問題。有的泛函的經驗性較小,有的經驗性則較高。如今也有的文章將HF、后HF、MCSCF、多參考方法等物理思想完全基于波函數的方法統稱為wavefunction theory (WFT),在討論時使用WFT一詞時DFT就不會和那些方法混淆了。
還有一個詞叫“第一性原理(first-principles)”,其字義和從頭算一樣,但“第一性原理計算”如今的主流指代是“量子化學方法研究周期性體系”,不僅包括嚴格的從頭算方法,也包括DFT,因為這類計算最常用的就是DFT。DFTB雖然依賴很多參數,但DFTB計算周期性體系也往往被不計較地算作第一性原理計算。
由于有了“第一性原理計算”這個專門描述把量子化學方法用于周期性體系的計算的詞,因此平時說的“量子化學計算”、“從頭算方法計算”一般是指計算分子、團簇這樣孤立(非周期性)體系的情況。那些通過量子化學方法主要研究孤立體系的程序被稱為量子化學程序,如Gaussian、ORCA、GAMESS-US等,而通過量子化學方法主要研究周期性體系的程序被稱為第一性原理程序,如CP2K、Quantum ESPRESSO等。注意“量子計算”和量子化學計算又不是一碼事,前者強調的是利用在量子計算機上實現的量子算法,可以但絕不限于做量子化學問題的研究。
接下來再說很知名的QM/MM。這個方法是指使用量子化學方法以量子力學(QM)的思想描述體系的一部分,用分子力場以分子力學(MM)的思想描述體系的另一部分,并且恰當考慮兩部分之間的耦合。對于很大的體系,這顯然比起全都用量子化學方法描述要便宜得多得多(MM部分計算耗時相當于QM部分的九豬一毛),但代價是MM區域描述的精度比QM區要差,而且絕大多數力場不能描述這部分發生的成鍵/斷鍵過程。因此,必須恰當劃分QM和MM區,讓最需要精確描述的部分或者涉及化學反應的原子納入到QM區中,而起到較次要作用的“環境”原子納入到MM區中。
還有一個詞是ONIOM,也是劃分不同區域,不同方法著重描述不同部分,它可以把任意兩種理論方法相組合。如果把量子化學方法和分子力場相組合,特稱為ONIOM(QM:MM),其用處和QM/MM類似但實現不同,描述時絕對不能搞混。一些相關討論見《要善用簇模型,不要盲目用ONIOM算蛋白質-小分子相互作用問題》(http://www.shanxitv.org/597)。
再說一下對電子激發態的描述。前面介紹的半經驗、HF、后HF、DFT等方法通過delta-SCF方式可以算激發態,但不夠普適。量子化學領域有很多專門的方法可以計算激發態,包括計算激發態的能量及其導數,如最常用的TDDFT、過時的CIS、較高精度的EOM-CCSD等,見《亂談激發態的計算方法》(http://www.shanxitv.org/265)。幾乎所有分子力場都是描述基態電子態的,但如果專門對激發態勢能面擬合力場參數,也可以用力場描述激發態,但已有的這樣的力場都是針對極其具體的體系的激發態擬合的,不具備普適性。機器學習勢同理。QM/MM也可以描述激發態,但僅限于電子激發完全發生在QM區的情況。
再簡單說一下和實際計算關系密切的基函數(basis function)的概念。本節介紹的理論方法,凡是基于量子理論思想提出的(也就是前面說的那些里面除了分子力場和機器學習勢以外的方法),在實際數值求解的過程中一般都要涉及分子軌道,關于分子軌道的概念詳見《正確地認識分子的能隙(gap)、HOMO和LUMO》(http://www.shanxitv.org/543)。絕大多數計算程序中都是把分子軌道展開成基函數的線性組合來描述的。最常見的基函數一類是原子中心基函數(如Gaussian等大多數量子化學程序以及CP2K等部分第一性原理程序用的高斯型基函數),其中心一般位于原子核,還有一類常見的基函數是平面波基函數,是大多數計算周期性體系為主的第一性原理程序用的,它的分布覆蓋整個被計算的晶胞。基組(basis set)是對于原子中心基函數而言的,例如6-31G*、def2-TZVP、cc-pVDZ等都是很常見的基組,它定義了實際計算時對各種元素原子具體用多少、什么參數的基函數。做HF、DFT、后HF、MCSCF、多參考等方法計算時都需要告訴計算程序用什么基組,基組質量越好,也就是越接近于所謂的完備基組極限,這些方法自身的精度發揮得就越充分,但代價就是耗時越高。一個好方法配一個爛基組,以及一個爛方法配一個好基組,結果都不理想,必須好方法配好基組才能得到較準確結果。半經驗、GFN-xTB方法計算時也利用基函數,但是用什么基函數是這類方法自身定義的,就不需要而且也不能再指定基組了。北京科音初級量子化學培訓班(http://www.keinsci.com/workshop/KEQC_content.html)和北京科音中級量子化學培訓班(http://www.keinsci.com/workshop/KBQC_content.html)都專門有一節對基組做詳細介紹,后者講得明顯更深、更廣。
3 任務類型與理論方法的結合
第2節介紹的各種理論方法原則上都可以用于第1節介紹的各種任務。例如,分子力場、DFT、QM/MM等理論方法全都可以用于幾何優化、振動分析、產生反應路徑等任務。這些組合在程序實現上一般沒有什么需要特殊考慮的,一個程序支持什么理論方法,就能基于它們做什么依賴于勢能面的任務。
搞明白了前面介紹的名詞,從頭算動力學(ab initio molecular dynamics, AIMD)和第一性原理動力學(first-principle molecular dynamics, FPMD)顧名思義自然就知道是描述什么計算了。這兩個詞其實沒有嚴格的區分,實際中經常混淆使用,但從嚴格的習俗來說,AIMD和FPMD分別最適用于描述使用量子化學方法對孤立體系和周期性體系做分子動力學模擬。所以北京科音CP2K第一性原理計算培訓班(http://www.keinsci.com/workshop/KFP_content.html)里面講CP2K做基于GFN-xTB和DFT的分子動力學的地方標題用的是第一性原理動力學,但若說成AIMD也完全可以,不會造成什么誤會。
由于基于分子力場做分子動力學的文章數目和流行程度遠高于非常昂貴的AIMD/FPMD,因此平時說的分子動力學模擬默認是指的基于經典力場的分子動力學,這也往往被叫做經典分子動力學。但要注意“經典”這個詞在不同語境下有不同含義,有的場合下是特指把原子核當做經典粒子來考慮,此時基于BOMD形式做基于量子化學方法的分子動力學也是經典分子動力學。而與之相對的是“量子動力學”,強調把原子核以量子力學方式描述,原子核有對應的波函數。顯然,此處“量子動力學”和“基于量子化學做分子動力學”又不是同一個概念。
QM/MM MD指什么也不言而喻,顯然是用的QM/MM理論方法做分子動力學任務,這結合了QM/MM對體系描述的特點和分子動力學研究問題的能力。顯然這比所有原子都用QM描述(相當于AIMD/FPMD)要便宜得多得多,當然代價就是MM區域在動力學過程中描述得相對較糙,而且預期不會發生化學反應,同時還得想辦法去找力場參數。因此能否用QM/MM MD代替AIMD/FPMD當然得根據被研究的體系和問題判斷,盲目瞎用純粹是自討苦吃(吐槽一下,很多初學者沒有基本理論常識,一看文獻里有QM/MM就覺得好像高大上似的,就整天想著QM/MM而不知道其局限性,太naive了)。
文獻里的許多用詞并不標準,必須結合語境和常識理解說的是什么。比如可能有的文章沒明確用QM/MM MD這個詞而只說了QM/MM,若實際上在此基礎上跑了動力學,當然就是QM/MM MD。再比如有的文章表面上說是做的AIMD,但從計算細節描述來看作者把一部分當做MM來描述以節約時間,顯然實際上也是QM/MM MD。理解名詞必須有基本的應變能力。
如果用的理論方法描述的是激發態,那么前述各種任務就是對激發態做的。比如用TDDFT做激發態分子動力學,那就是動力學的每一步用的原子受力都是用TDDFT算的激發態的受力。順帶一提,有些文獻里聲稱做的是激發態動力學研究,但其實內容里根本沒做分子動力學,只是對激發態計算了勢壘,文中這么說只是由于勢壘和研究反應速率的反應動力學領域里的反應速率常數密切相關。另外值得注意的是研究激發態動力學往往需要考慮內轉換、系間竄越等勢能面切換的過程,考慮這些需要做非絕熱動力學,需要額外的算法,這方面的坑很深。所以并不是一個程序支持了計算激發態的理論方法和分子動力學模擬后就能完美、嚴格地做激發態動力學研究相關問題,情況遠沒那么簡單。
]]>On the possible reasons why data in computational chemistry literature cannot be reproduced
文/Sobereva@北京科音 2023-Aug-1
0 前言
經常有做計算化學的人在網上問為什么他沒法重復出來文獻里的計算數據。導致重復不出來的原因實在太多了,然而初學者提問此類問題時幾乎總是含糊其辭,提供的有效信息甚少,導致別人根本無從回復,或者需要別人羅列一大堆可能導致差異的原因。我感到每次回復此類問題太費事,于是在這里專門寫個文章說說這事。遇到這種問題的讀者仔細看完此文后,應該能料想出可能是什么原因導致自己和文獻的結果存在差異。就算還搞不明白,至少也應該能明白在網上問別人的時候應當提供什么信息,知道怎么把導致差異的可能原因的范圍盡可能縮小,免得別人打很多字羅列諸多當前不需要考慮的可能性,或者別人嫌你提供的有效信息完全不夠而根本不想回復。
這里首先要強調一點的是,如果你的目的就是為了精確重復文獻數據,那你就要盡最大可能使用和文獻完全相同的方式去做計算,而不要管人家的做法合不合理,哪怕你明知道人家的計算方式不當。下文說的內容都是為了讓你能盡可能準確重復出文獻里的數據,而不是講怎么合理地計算。如果你的實際目的是想獲得相同體系相同研究問題的合理的結果,那你只要確保你自己的計算是合理的就行了,沒必要非得把別人的數據重復出來,說不定人家的計算本來就有問題。如果最終驗證發現別人的計算有硬傷并因此導致結論錯誤,或者憑基本知識就能斷定別人的計算有問題,那么可以發一篇comment文章指正以免以訛傳訛,比如《我對一篇存在大量錯誤的J.Mol.Model.期刊上的18碳環研究文章的comment》(http://www.shanxitv.org/584)里介紹的文章。
1 結構不一樣
自己計算用的結構和文獻不一致,是導致數據無法重現的最常見原因之一。如果你用的結構就是文獻正文或補充材料里給的坐標,那就可以直接排除這個因素了。注意有些文獻的SI里鍵長、笛卡爾坐標單位是Bohr而不是埃,千萬別弄錯了。
如果你計算的基本結構特征都和文獻里不符,也即算的都不是同一個東西,能重現出文獻里的數據就怪了。很多體系有不同的形態,比如酚酞在酸性、中性、堿性環境下主要的存在形態明顯不一樣,氨基酸在真空和水環境下的質子化態明顯不一樣,姜黃素在水和有機溶劑中一種是烯醇式一種是酮式結構,等等。你必須確保你算的和文獻里算的確實是同一種狀態的結構,如果文獻里給了截圖,一定要仔細對照。
做計算要有基本的化學常識,并且要認真仔細,免得搭出來沒意義的結構去做計算,自然和文獻里對不上。比如文獻里給出Lewis結構式時通常是隱去碳上的氫的,如果計算的時候真不畫氫,或者少畫了個別的氫,自然計算毫無意義。再比如,文獻里算一個羧基配位的過渡金屬配合物,如果你在計算時羧基上還留著氫,明顯也是錯的。再比如,文獻里畫了一個帶一個小配體的過渡金屬配合物的Lewis式,若你算的是水溶液中的狀態并忽略了配位水分子,也自然是錯的。再比如,文獻里給出一個聯苯或者碗烯的二維結構式,看上去是在一個平面上,若你去計算其基態時真的擺成平面來優化,得到的也是大概率是錯誤的結構(有破壞平面的虛頻的結構)。還要注意一些結構的構建不要想當然,比如SiO2表面在水中時表面的O主要是以羥基及其去質子化形態存在的,比例和pH有關,如果都當成是烏禿禿的氧就錯了。結構構建的關鍵性信息在文獻里一般都會有具體說明,但也可能一些文獻中在描述上有疏漏。
有些體系在計算的時候結構構建方式不唯一,比如《要善用簇模型,不要盲目用ONIOM算蛋白質-小分子相互作用問題》(http://www.shanxitv.org/597)、《18碳環(cyclo[18]carbon)與石墨烯的相互作用:基于簇模型的研究一例》(http://www.shanxitv.org/615)和《使用量子化學程序基于簇模型計算金屬表面吸附問題》(http://www.shanxitv.org/540)里提到的簇模型,怎么構建簇明顯會影響結果,特別是當簇用得較小的時候。若要重復文獻里的數據,就要用盡可能相同的模型,哪怕其模型很昂貴。
很多分子有不止一種構象(勢能面極小點),柔性大分子甚至有一萬種以上的構象。幾何結構優化一般會優化到與初始結構最接近的勢能面極小點。而不同構象下計算的屬性可能有不小差異,因此你必須確保你用的構象和文獻里一致,也即結構優化使用的初猜結構要盡可能像文獻里給出的。如果文獻沒明確給出三維結構信息,按理說文獻應當用的是能量最低構象(確切來說是自由能最低構象)做的計算,但也有可能作者忽略了構象搜索并得到了不合理的結果。如果你對構象搜索一點概念都沒有,建議看下文了解些常識
《使用molclus程序做團簇構型搜索和分子構象搜索》(http://bbs.keinsci.com/thread-577-1-1.html)
《gentor:掃描方式做分子構象搜索的便捷工具》(http://bbs.keinsci.com/thread-2388-1-1.html)
《將Confab或Frog2與Molclus聯用對有機體系做構象搜索》(http://bbs.keinsci.com/thread-20063-1-1.html)
《使用Molclus結合xtb做的動力學模擬對瑞德西韋(Remdesivir)做構象搜索》(http://bbs.keinsci.com/thread-16255-1-1.html)
也不是所有情況都適合用能量最低構象來計算,比如某化學反應可能是從某個能量相對較高的構象發生的,可以對反應的IRC的反應物一端做幾何優化得到之。
團簇體系的構型搜索和柔性分子的構象搜索同等重要。哪怕水二聚體這么簡單的兩個小分子構成的團簇都都有不同的極小點構型,并且對應的結合能明顯不同。因此計算這種體系也必須確保和文獻用的構型相一致。如果文中沒明確交代,一般默認其用的是能量最低構型結構做的計算,但也可能作者忽略了這個問題,導致誤用了能量不是最低的構型并因此得到了錯誤的結果。如果你對構型搜索沒有概念,建議看此文:《genmer:生成團簇初始構型結合molclus做團簇結構搜索的超便捷工具》(http://bbs.keinsci.com/thread-2369-1-1.html)。
有的時候兩種極小點構型或構象可能結構相差很小。這種情況需要把可視化程序里的視角和文獻里的圖片擺得盡可能一致再去觀察,免得算的其實不是同一個結構。
上面說的是計算極小點結構的情況,自不必說,重復文獻里過渡態的計算結果時也必須嚴格確保和文獻里用的結構一致。
對于研究固體表面的情況,要注意文獻里的結構是怎么來的。表面是從體相直接切出來的未經優化的(unrelaxed),還是經過優化的(relaxed),還是使用的考慮表面重構的(reconstructed),這需要區分清楚。文獻中計算用的是具體哪個晶面也必須要搞清楚。固體表面吸附問題也有類似構象/構型搜索的勢能面存在多種極小點問題,一個小分子可能在表面上不同位點以不同方式吸附,實際算的結構必須和文獻相一致。文獻里算的吸附是物理吸附還是化學吸附也得搞清楚。對于吸附過程有勢壘的情況,初猜結構中你把被吸附物和表面擺得相距很近,一般優化完了的是形成新鍵的化學吸附,如果擺得較遠,一般得到的是弱相互作用維持的物理吸附,二者的結構、相互作用能相差甚大。研究表面吸附還有覆蓋率的問題,要注意文獻中對所用結構的相關描述,研究低覆蓋率和飽和覆蓋率時用的模型明顯不同。
用slab模型研究固體表面還要注意厚度問題。slab太薄的話,得到的功函數、吸附能等性質都不準確。對于二維層狀材料的研究,還要注意層數對計算的性質的影響。這些方面都應當和文獻嚴格一致。對表面類體系優化時還經常牽扯到對一部分原子凍結使之固定為體相的結構,之后振動分析也相應地牽扯凍結,凍結方式必須和文獻一致。
做某些體系的分子動力學模擬也同樣要注意初始結構的差異,否則現象可能和文獻不符。比如有文獻研究表明水中的蛋白質由于疏水效應會自發進入口徑足夠大的碳納米管,如果你一開始把蛋白質放得離碳納米管老遠,由于質量頗大的蛋白質本身整體運動就較慢,再加上碳納米管的隨意旋轉(沒凍結的話),可能文獻里說的那種蛋白質自發進入管內的現象跑挺長時間也出現不了。再比如想模擬結冰過程,哪怕一開始把溫度設得顯著低于冰點,但沒有在水中加入局部的冰的結構的話,跑很長時間也不會看到冰的結構的出現。至于在模擬的時間尺度內一定會出現的現象,初始結構就不重要了。比如水和乙醇的互溶,無論初始結構里把二者混合均勻,還是分成兩相,最后肯定都是互溶的。
做周期性體系的模擬還要注意盒子尺寸與文獻要一致。用第一性原理計算固體時,假設k點數是固定的,盒子尺寸的不同會影響精度。做動力學模擬時,盒子尺寸還間接影響原子運動行為以及模擬得到的屬性。
用Quantum ESPRESSO等平面波程序時,以及CP2K這種將平面波當輔助基函數的程序時,如果算的是某些維度為非周期性體系,還需要注意真空層的厚度,要盡可能和文獻一致。因為真空層可能對結果有不可忽視的影響,比如影響非周期性方向上與相鄰鏡像的作用是否可以忽略。而且比如CP2K里用MT的Psolver時還有非周期性方向上盒子尺寸大于相應方向有電子密度明顯分布的兩倍以上的要求,顯然真空區不能小了。
假設文獻用的是實驗測定的坐標直接進行性質的計算,還要注意實驗來源必須一致。比如文獻或晶體數據庫里對同一種晶體結構可能提供了不同溫度下測定的坐標,會有一定程度的不同(體現熱膨脹)。顯然壓力也直接影響測定的結構。哪怕是相同的測試環境,不同來源的晶體結構也會有差異,特別是氫的位置的確定,無疑這對氫鍵等問題的計算結果會有直接影響。做量子化學/第一性原理研究的人一般都會至少對氫的坐標重新進行優化來refine之,需要注意文獻里是怎么考慮的。蛋白質的高解析度和低解析度測出來的晶體結構里殘基側鏈的位置也可能相差甚大,甚至明顯影響到做酶催化、分子對接之類問題的結果。同樣的屬性,以不同類型實驗測定的結果注定也會有差異,比如氣相電子衍射和單晶衍射測的一個是氣相結構一個是晶體結構,對于柔性分子差異可能很大,這點參考《實驗測定分子結構的方法以及將實驗結構用于量子化學計算需要注意的問題》(http://www.shanxitv.org/569)。
上面列舉了諸多結構層面影響計算結果的可能性,當然不可能列舉得很完備,實際情況多種多樣。總之希望讀者能意識到嚴格保證和文獻里用的結構的一致對于重現數據有多么重要。
2 計算設置不一樣
為了精確重復文獻數據,要盡可能仔細閱讀文章及其補充材料,了解清楚文獻計算細節,使得自己的計算設置能最大程度與文獻相一致。本節里談到的很多可能導致差異的因素在《談談不同量子化學程序計算結果的差異問題》(http://www.shanxitv.org/573)里都有詳細說明,務必注意閱讀。
量子化學和第一性原理計算用的理論方法,以及理論方法中涉及的設定和參數(如范圍分離泛函的w參數、色散校正的經驗參數、CASSCF和多參考方法的活性空間的選擇、TDDFT計算是否用了TDA近似、DFT+U參數、CASPT2計算用的IPEA shift參數、DLPNO方法用的閾值、GW@DFT和DFT-SAPT具體基于什么泛函、sTDA計算用的經驗參數,等等)必須和文獻精確一致。有的理論方法在同一個程序里甚至有兩種定義,比如B3LYP在ORCA里寫成B3LYP還是B3LYP/G是不同的,要搞清楚文獻實際用的哪個(通常是前者)。還要注意理論方法名和關鍵詞的差異,比如里這里提及的:《Gaussian16里用PBE0關鍵詞計算的實際上是PBE0-DH雙雜化泛函》(http://bbs.keinsci.com/thread-13660-1-1.html)。有的文獻的寫法還可能存在含糊性,比如可能文獻就說對某個開殼層體系用了二階微擾理論,但實際上二階微擾理論用于開殼層的實現形式有一堆,比如UMP2、PUMP2、ROMP2、ZAPT2、ROMP、OPT2等等,如果文中給了引用的文獻,要根據文獻判斷具體是哪種。
對計算結果可能有明顯影響的各種條件必須一致,比如:
? 溶劑效應的考慮。如果用的是隱式溶劑模型,那么用的具體是什么方法?描述的是哪種溶劑?用CP2K的SCCS模型時α、β、γ參數是怎么設的?描述混合溶劑的時是怎么確定溶劑參數的?如果用的是顯式溶劑模型,那么溶劑分子排布是怎么考慮的?有沒有同時用隱式溶劑模型?
? 計算熱力學校正量的模型。比如《使用Shermo結合量子化學程序方便地計算分子的各種熱力學數據》(http://www.shanxitv.org/552)里介紹的Shermo程序默認用的以及ORCA用的是Grimme的QRRHO模型,而Gaussian用的是較原始的不適合含低頻體系的RRHO模型
? 計算熱力學量時是否考慮了平動和轉動,顯然算周期性體系時不應當考慮(在Shermo程序中這由settings.ini里的imode決定)
? 計算轉動對熱力學量貢獻時對轉動對稱數的考慮,看Shermo手冊附錄部分了解相關常識
? 計算熱力學校正量、振動分析用的原子質量
? k點數目和分布
? 平面波相關計算的截斷能
? CP2K中,做雜化泛函時用的庫侖截斷半徑、DFT+U計算用的布居計算方法以及考慮的角動量、Poisson solver的選擇
? 對相對論效應的考慮
? 對外場/外勢的考慮
? DFT積分格點精度。參看《密度泛函計算中的格點積分方法》(http://www.shanxitv.org/69)
? 是否用了凍核、怎么凍的
? 雙電子積分的積分屏蔽設置
? 是否用了RI、DLPNO等加速計算方式
? 是否考慮了偶極校正
? QM/MM計算劃分的位置、MM與QM區之間的相互作用的考慮、link原子的設置
等等等等
基組必須和文獻嚴格一致,并注意上述http://www.shanxitv.org/573博文里說的許多細節問題。注意一個基組/贗勢名可能有不止一個指代,比如Stuttgart贗勢,有不同方式考慮相對論效應的版本、不同價電子數和氧化態的版本,Gaussian內置的和Stuttgart官網上的贗勢和贗勢基組定義往往又有所不同。再比如,GAMESS-US用戶寫CCD和CCT關鍵詞分別用的是cc-pV(D+d)Z和cc-pV(T+d)Z,而不是更常見的cc-pVDZ和cc-pVTZ。要弄清楚作者實際用的什么,仔細看文中的描述,并注意作者引的基組原文。
不光一般意義上的基組(叫主基組或者叫軌道基組)要和文獻計算時的一致,輔助基組也應當一致。輔助基組種類很多,比如RIJ用的/J輔助基組,RIJK用的/JK輔助基組,電子相關計算用的/C輔助基組,CP2K里加快雜化泛函計算用的ADMM輔助基組,CP2K里做LRIGPW計算用的輔助基組,等等。同一個主基組能夠或者適合搭配的某種目的的輔助基組可能不止一種,而且有的時候有含糊性和任意性,比如ORCA里用ma-def2-TZVP主基組時,可能有人用autoaux關鍵詞自動產生輔助基組,可能有的人用標準的def2/J輔助基組。
對于基于經典力場的模擬,力場參數顯然必須和文獻嚴格一致。如果參數是從文獻里拷來然后用在自己計算中的,注意單位轉換,以及1-4相互作用規則和LJ參數的混合規則等細節必須和文章相同。文獻給出的LJ參數有的是R0有的是σ需要區分。原子電荷也必須和文獻保持一致,如果原子電荷是作者自己算的,要搞清楚計算原子電荷的方法,并且如果是基于波函數算的,那么波函數是在什么幾何結構、溶劑環境、計算級別下得到的要弄清楚。這點很重要,比如對于RESP電荷,氣相下計算的和水環境下計算的,Hartree-Fock和B3LYP計算的,相差大了去了,參看這些討論:《RESP擬合靜電勢電荷的原理以及在Multiwfn中的計算》(http://www.shanxitv.org/441)、《RESP2原子電荷的思想以及在Multiwfn中的計算》(http://www.shanxitv.org/531)。
做動力學模擬的情況,必須確保模擬相關設置和文獻一致。比如步長、步數、坐標/速度/受力/能量保存頻率、參考溫度和壓力、控溫和控壓方法、熱浴和壓浴的時間常數、可壓縮系數、各向同性還是各向異性控壓、初速度怎么產生的、范德華和靜電作用的計算方式(如簡單截斷、twin-range、Ewald、PME、SPME等,以及其中涉及的截斷半徑,是否用了switching function等處理)、水模型是剛性還是柔性的、是否用了鍵/鍵角約束、用沒用能量/壓力色散校正,等等。
如果你用的計算程序和文獻里不同,或者和文獻里的相同但版本不同,那么由于默認設置不同,以及算法實現的不同,可能對結果帶來很大差異,一定要仔細閱讀《談談不同量子化學程序計算結果的差異問題》(http://www.shanxitv.org/573)。
在量子化學波函數分析領域也有很多細節設置會影響分析結果。這里以非常流行的波函數分析程序Multiwfn(http://www.shanxitv.org/multiwfn)為例:
? 按照《使用Multiwfn做電子密度、ELF、靜電勢、密度差等函數的盆分析》(http://www.shanxitv.org/179)、《使用Multiwfn的定量分子表面分析功能預測反應位點、分析分子間相互作用》(http://www.shanxitv.org/159)、《使用Multiwfn對靜電勢和范德華勢做拓撲分析精確得到極小點位置和數值》(http://www.shanxitv.org/645)等文章介紹的方法進行分析時,格點間距數值越小精度越高,但也越耗時
? 按照《使用Multiwfn繪制態密度(DOS)圖考察電子結構》(http://www.shanxitv.org/482)繪制PDOS和OPDOS圖時,在Multiwfn里選擇的計算軌道成份的方法會直接影響結果
? 按照《使用Multiwfn模擬掃描隧道顯微鏡(STM)圖像》(http://www.shanxitv.org/549)和《使用Multiwfn結合CP2K的波函數模擬周期性體系的隧道掃描顯微鏡(STM)圖像》(http://www.shanxitv.org/671)繪制STM圖時,偏壓的數值和常高模式掃描的平面的選擇都會明顯影響結果
? 計算《衡量芳香性的方法以及在Multiwfn中的計算》(http://www.shanxitv.org/176)和《使用AdNDP方法以及ELF/LOL、多中心鍵級研究多中心鍵》(http://www.shanxitv.org/138)里介紹的多中心鍵級時,基于原本的基函數和基于自然原子軌道(NAO)計算會得到不同的結果
? 計算Hirshfeld原子電荷時需要用到原子自由狀態下的密度。用自行提供的原子波函數文件來計算此密度,還是直接用Multiwfn內置的此密度,會有所不同。
本節提到的這些計算細節是理應充分體現在文章的computational details里或者補充材料里的。但由于一些文獻的作者為了省篇幅,或者用的很多設置和程序默認的一致,或者由于作者計算水平比較外行、意識不到很多細節對計算非常重要,就在文中沒特意說。如果有些要點不知道作者具體怎么考慮的,自己把各種可能性都試試就知道了,文章沒特意說的設置就姑且用程序默認的。
3 計算的電子結構狀態不一樣
凈電荷和自旋多重度的設置必須和文獻里的相同,否則相當于算的是其它電子態,自然算出來的各種性質都不同。比如計算基態的氧氣發生的反應、計算富勒烯的原子化能,如果氧氣和碳原子誤當成了單重態來算,顯然結果是錯的。此外,稍微了解點兩態反應性的概念就會知道,不少體系在不同自旋態下反應機理都明顯不一樣,如果自旋多重度或凈電荷設錯了,自然反應物/產物/中間體/過渡態等無法得到和文獻里一致的結果,而且相差懸殊。
如果文獻沒注明、從文獻中看不出相關信息,那么凈電荷一般為0。如果被研究的體系的自旋多重度不那么顯而易見,或者研究中涉及到了不止一個自旋態,文中一般都會說明自旋多重度。如果確實沒說,那就得查閱文獻或者數據庫,或者自己判斷、測試了。
很容易被忽略的是開殼層單重態或者叫自旋極化單重態。用KS-DFT等方法來計算的話應當做對稱破缺計算,參看《談談片段組合波函數與自旋極化單重態》(http://www.shanxitv.org/82)。比如整體為單重態的反鐵磁性耦合體系、雙自由基體系、共價鍵被拉長的均裂狀態就是最典型的例子。還有一些特殊的體系也是如此,比如18碳環的D18h點群的過渡態結構、乙烯二面角扭轉成90度的結構、六并苯。重復文獻里的這些體系的計算時別誤當成了閉殼層單重態來計算(文中如果也是做了對稱破缺計算,一般都會明確說。如果沒說,沒準文獻也誤當成了閉殼層計算)。
對于第一性原理計算磁性材料時必須謹慎,很多情況下不是光設個整體的自旋多重度就完事的,而必須恰當設置初始磁矩才能收斂到真正要考察的磁性狀態。為了重復文獻(或材料數據庫)中的數據,若它們給了收斂的波函數對應的各個原子的自旋磁矩/自旋布居信息的話,最好根據其來設置初猜波函數里的原子自旋磁矩,以盡最大可能收斂到和文獻相同的波函數狀態。
要注意波函數穩定性問題。即便凈電荷、自旋多重度的設置是正確的,也不代表SCF收斂后得到的波函數就是實際想研究的態、和文獻里算的狀態相一致。如果文獻里研究的是基態,你算的結果和文獻對不上,而且體系又不是簡單有機體系而是電子結構特殊的體系,那么應當做一下波函數穩定性檢測,比如Gaussian里可以用stable關鍵詞,發現不穩定的話可以用stable=opt嘗試搞出穩定波函數。不穩定的波函數可能意味著這是某個激發態,還可能意味著此波函數是沒有任何物理意義的虛假的狀態。
4 計算的東西或方式不一樣
重復不出文獻的數據時還要想清楚到底你算的東西、計算的方式是否和文獻一致、有可比性。下面列舉一些典型的需要注意的情況。
比如通過能量差E(AB)-E(A)-E(B)考察倆分子A和B間相互作用強度,復合物結構肯定是要優化的,而單分子是直接從復合物優化后的結構里直接取出來,還是也做優化,這在不同文中的做法就不一樣了。單分子不優化情況下得到的能量差一般稱為(復合物結構下的)相互作用能,單分子也優化情況下得到的能量差一般稱為結合能,二者之間相差各個單體的變形能之和。對于諸如《透徹認識氫鍵本質、簡單可靠地估計氫鍵強度:一篇2019年JCC上的重要研究文章介紹》(http://www.shanxitv.org/513)里面列舉的那些剛性小分子,相互作用能和結合能差異甚微,但如果考察的是兩個容易變形的分子間的作用強度,比如兩個氨基酸分子的結合,那么相互作用能和結合能就必須明確區分了。J. Chem. Phys., 158, 244106 (2023)還專門討論了什么情況變形能會較大。對于鍵能,也是類似地有不同計算方式。所以研究此類問題的時候一定要搞清楚文獻具體是怎么算的。
再比如做SAPT能量分解計算,會得到很多耦合項,比如交換與色散作用的耦合項,這是歸到色散項里,還是歸到交換互斥項里,不同文章的做法可能不一樣,需要注意文章怎么說的。再比如計算反應的自由能問題,是計算標準反應自由能,還是計算特定濃度下的反應自由能,這是不一樣,相差濃度校正項,要搞清楚文獻實際算的是什么。再比如電子親和能、電離能、激發能,都有垂直和絕熱之分,文獻里計算哪種都有,也必須確保和文獻算的東西對應。
文獻里有時候對熱力學量的標注比較含糊,要分清楚文獻算的是什么溫度下什么量。比如E,文獻里可能指電子能量,也可能指內能,需要結合語境判斷。
模擬ECD譜需要轉子強度,有長度形式和速度形式兩種,諸如Gaussian都會輸出,在Multiwfn里按照《使用Multiwfn繪制紅外、拉曼、UV-Vis、ECD、VCD和ROA光譜圖》(http://www.shanxitv.org/224)里說的繪制ECD時可以選采用哪種,一般推薦用速度形式。如果你用的和文獻不一致,會導致峰型存在一定差異。
基組的CBS外推的方法不唯一,有不同公式,有的情況外推方式里也涉及到參數,參看《談談能量的基組外推》(http://www.shanxitv.org/172)。不光是能量外推,還有比如GW計算的準粒子能量隨基組的外推、幾何結構隨基組的外推等。一些文獻對高級別理論方法結合大基組還用一些近似方式估計,比如一種常見的是CCSD(T)/大基組 = CCSD(T)/小基組 + (MP2/大基組-MP2/小基組),這在《各種后HF方法精度簡單橫測》(http://www.shanxitv.org/378)里專門說了。涉及到這些高精度數據估算時,需注意保證和文獻的做法一致。
還有一些量本來就沒有唯一定義,去重復文獻的數據更是得弄清楚文獻里用什么定義、什么方法算的。比如自由體積,我在《使用Multiwfn計算晶體結構中自由區域的體積、圖形化展現自由區域》(http://www.shanxitv.org/617)里介紹了一種合理的計算方式,但顯然這不是唯一方式。再比如分子半徑,我在《談談分子半徑的計算和分子形狀的描述》(http://www.shanxitv.org/190)就已經列舉了多種計算方式。還有諸如原子電荷,計算方法更是多了去了,如ADCH、RESP、Hirshfeld、NPA等,簡要介紹見《原子電荷計算方法的對比》(http://www.whxb.pku.edu.cn/CN/abstract/abstract27818.shtml)。
為了正確理解文獻具體算的是什么,必須把背景知識搞清楚,典型的就是gap這個概念,有HOMO-LUMO gap、band gap、optical gap、fundamental gap等,參見《正確地認識分子的能隙(gap)、HOMO和LUMO》(http://www.shanxitv.org/543)。如果沒搞清楚概念和定義方式,可能重復不出文獻的數據,或者實際上文獻的計算方式或用詞不當,你卻意識不到這一點。
某些問題的計算中可能涉及到一些實驗值,要搞清楚作者用的什么值。比如用量子化學程序計算含碳物質的生成焓,通過構造熱力學循環可知其中需要利用實驗的(或第一性原理計算的)石墨的升華焓,要搞清楚這個量是從哪來的,具體是多少。再比如, 量子化學計算某分子的標準氧化還原勢,其中利用到標準氫電極的電勢,其數值有不同來源,從4.05到4.44 V都有報道,Phys. Chem. Chem. Phys., 16, 15068 (2014)建議對理論計算的情況用4.28 V。
還有一些研究涉及到一些額外的參數需要注意,典型的就是頻率校正因子,見《談談諧振頻率校正因子》(http://www.shanxitv.org/221)。是否使用頻率校正因子,以及對某一特定級別使用什么目的的、哪個來源的校正因子,都會影響結果。
周期性體系的計算中,軌道能量的絕對數值是沒意義的,不同程序用的能級零點也不一樣,需要關心的只有相對數值,比如帶隙。所以不要問為什么DOS圖的形狀和文獻一致但橫坐標和文獻不一致。這也正是為什么文獻在繪制DOS圖時往往一般把價帶頂或者費米能級位置設為0點,因為這樣才便于公平對比。
還有些量在文獻里用的習俗和你用的可能不同。比如算結合能問題,有少數文章把結合過程的能量降低量作為正值記錄。再比如NBO給出的E2超共軛作用能,程序輸出時把正值作為超共軛作用造成的體系能量降低,但有的文獻報道E2值的時候取的是負值。
如以上列舉的情況可見,算某個東西的時候必須仔細閱讀文獻搞清楚作者是怎么算的、用的什么定義、算的到底是什么。
5 數據的可重現性本身就差
有些數據很容易重現,比如在RHF/6-31G**級別下優化水分子的基態結構,不管用什么主流量化程序、怎么優化,得到的都是相同結果,初始結構很隨意。有些數據本身就是難以精確重現,典型的就是凝聚相體系的分子動力學。由于分子動力學過程有混沌效應,而且實際計算中往往不可避免地引入隨機因素,會導致文獻中的動力學模擬的定量結果幾乎無法嚴格精確重現。關于這點我專門寫過文章,參看《數值誤差對計算化學結果重現性的影響》(http://www.shanxitv.org/88)。更具體來說也看重現文獻里的什么動力學模擬數據。比如小分子的液態性質相對來說是容易重復的。比如重復密度值,文獻里是801.92 g/L,你算出來801.88 g/L,這就可以認為是很好重復出來了。如果你算出來是810.21 g/L,而且模擬流程和設置是合理的,那就是有明顯不可忽視的差異了,已經超過了隨機性的影響了,需要根據前面所說的來考慮導致與文獻存在差異的可能原因。也有的量的重現相對比較困難,比如磷脂膜里插入了一個分子,去計算它的側向擴散系數,這就屬于相對比較難算準的,因為本身分子在磷脂膜這種擁擠的環境里擴散就困難,而且體系里就這么一個分子,沒法通過同類分子的平均來減小統計誤差。就算你自己跑的時間非常長以保證統計精度絕對足夠高,但文獻里給出的數據未必統計精度就夠高。像這種問題,對文獻里的數據的重現精度就別要求太高了。
還有一種情況是動力學模擬的現象在有必然性的同時本身也有一定隨機性,跑出什么現象有運氣成分。比如距離蛋白質的口袋一定距離處放一個小分子配體,在水環境下做動力學模擬,考察2 ns模擬時間內配體能否和蛋白質結合,初速度隨機生成。像這種模擬的結果就很有隨機性,如果跑10次模擬,可能有的模擬剛過幾百ps小分子就進入口袋了,也可能有的模擬開始后小分子恰好往蛋白質相反方向游離,跑到2 ns還沒進入口袋。對于這種問題的研究必須做大量的模擬來得到統計結果,較嚴謹的文獻普遍都會這么考察這種現象明顯有隨機性的問題,你若要重復文獻也必須以相同的方式去模擬。如果模擬的樣本數不夠多的話,也不要指望結果特別相符。比如前述問題,可能文獻里跑10次發現有5次進入口袋,你模擬10次發現有3次進入口袋,這未必是模擬設置和文獻有區別,而純粹是隨機性所致,要以正確的態度來看待這種情況。
順帶一提,量子化學、第一性原理做靜態的計算的可重復性比起分子動力學模擬要好得多得多,但也不排除極個別情況前者可能受到隨機性的明顯影響。比如對勢能面很復雜的大分子進行優化,特別是QM/MM計算時可能牽扯到幾千原子的情況的優化,有可能由于微小的隨機性因素(如使用了并行計算所帶來的)導致兩次優化分別收斂到了勢能面上可能相距挺遠的兩個極小點,且有肉眼可察覺的差異。
6 對相符程度要求過高
有人其實可能已經合理重復出了文獻中的數據,但由于他對重復的精度要求過高,導致誤以為沒重復出來。
頭腦里要有收斂限的概念。比如文獻里優化的結構二面角是123.64度,你優化出來的是123.69,這就可以認為是重現出來了,因為這點差異通常都已經小于計算程序的幾何優化的默認收斂限了,差異基本來自初始結構的任意性。再比如,文獻里DFT計算出的反應能是-8.12 kJ/mol,你算出來的是-8.18 kJ/mol,也完全可以接受了。如果本來你用的計算程序和文獻里都不同,在盡可能令設置和文獻相同的情況下,你算出來比如是-8.32 kJ/mol也可以算重復出了文獻,各種雞毛蒜皮不值得一提的因素足矣帶來這種程度的差異。但如果你算出來是比如-9.8 kJ/mol,那就明顯不是不值得一提的差異了。再比如TDDFT計算電子激發能、DFT計算HOMO能級,和文獻里相差0.02 eV,這都可以算一致,但如果相差到0.1 eV,這就不算一致了,畢竟TDDFT算激發能的精度都在0.3 eV左右(泛函選擇得當的前提下),當差異達到接近方法本身的誤差的數量級時明顯就算顯著差異了。
重復文獻數據的時候用的收斂限應當足夠嚴,起碼令收斂限顯著小于你期望的對文獻數據的重現精度。雖然文獻作者用的收斂限未必夠嚴,因此光是你把收斂限設嚴未必有意義,但至少先做自己這里能做的事。
7 自己的計算存在硬傷
重復不出文獻數據有可能是自己計算存在硬傷導致的。初學者缺乏常識、經驗和敏銳性,計算很容易存在硬傷,例如:
? 關鍵詞沒寫對或設置不當,導致數據沒意義,比如:Gaussian里想要用PBE0泛函但寫的關鍵詞是PBE0(此時做的是PBE0-DH泛函計算)、用贗勢基組時只定義了基組部分而沒定義贗勢、自定義基組時漏定義了某些原子或元素、Gaussian里用IOp自定義泛函時用opt freq關鍵詞(IOp沒法自動傳遞到freq這一步導致振動分析不是在與優化相同級別勢能面的極小點計算的)、Gaussian里用后HF方法算偶極矩時沒寫density結果得到的是HF級別的、計算UV-Vis光譜時算的態數太少導致光譜不夠完整、CP2K計算時用雜化泛函并且基于密度矩陣做積分屏蔽時沒讀取純泛函波函數當初猜(《解決CP2K中SCF不收斂的方法》http://www.shanxitv.org/665文中提到了)、CP2K算磁性體系時沒寫UKS結果當成了閉殼層算、Gaussian里按照特定方向加電場計算時不知道要寫恰當用nosymm導致電場加的方向和期望的不符(nosymm用處見《談談Gaussian中的對稱性與nosymm關鍵詞的使用》http://www.shanxitv.org/297)、用sobtop(http://www.shanxitv.org/soft/Sobtop)直接產生拓撲文件后沒有給里面添加原子電荷、用sobtop產生拓撲文件時誤把可旋轉二面角以諧振勢對待、用Multiwfn做空穴-電子分析時沒按照《使用Multiwfn做空穴-電子分析全面考察電子激發特征》(http://www.shanxitv.org/434)說的在Gaussian輸入文件里寫IOp(9/40=4),等等
? 缺乏基本知識瞎算,比如:計算小晶胞體系不知道考慮k點、算極化率時不知道要帶彌散函數、B3LYP算色散主導的弱相互作用卻不加色散校正、CP2K里用MOLOPT基組計算需要CUTOFF很高的Na的時候用的CUTOFF不夠、界面體系用了各向同性控壓而不知道應該用半各向同性控壓、算氣-液界面體系在垂直于界面方向開了控壓結果導致真空區消失、用Multiwfn基于CP2K產生的molden文件分析前沒在里面添加盒子信息(參見《詳談使用CP2K產生給Multiwfn用的molden格式的波函數文件》http://www.shanxitv.org/651)、做Mulliken布居分析用的基組帶了不該帶的彌散函數、算溶劑環境下溶質自由能的時候忘了考慮標準態濃度轉換問題(參看《談談隱式溶劑模型下溶解自由能和體系自由能的計算》http://www.shanxitv.org/327)、試圖用后HF方法計算分子軌道(卻渾然不知程序雖然給出了結果但實際上是HF部分產生的)、用背景電荷表現環境分子的勢場用的是對靜電勢重現性極爛的QEq電荷(相關討論看《基于背景電荷計算分子在晶體環境中的吸收光譜http://www.shanxitv.org/579),等等
? 計算流程/方式不對,比如:算高精度能量和性質之前結構沒經過幾何優化、直接把IRC兩端的結構當做反應物和產物的準確結構用于計算能量和屬性數據、振動分析和IRC計算之前結構沒有在嚴格相同級別下優化過、對動力學軌跡計算某個分子的RMSD衡量內部結構變化的時候不知道先要消除整體平動和轉動、算電子發射光譜之前沒優化激發態、模擬拉曼光譜時沒按照《使用Multiwfn計算特定方向的UV-Vis吸收光譜》(http://www.shanxitv.org/648)里說的將拉曼活性轉化成拉曼強度
? 數據讀取錯誤。比如Gaussian里做了雙雜化泛函計算,結果讀成了其中SCF Done后面的中間量(怎么正確讀看《談談該從Gaussian輸出文件中的什么地方讀電子能量》http://www.shanxitv.org/488)。再比如做幾何優化,Gaussian會對初始和最終結構都做布居分析,本來想讀最終結構下的,結果誤讀成第一次輸出的。再比如做開殼層體系的NBO分析時,NBO會對總密度矩陣、alpha密度矩陣和beta密度矩陣的分析結果依次輸出,如果讀錯地方就糟糕了
? 對計算數據質量缺乏把控。如果數據質量太糟糕,自然可能無法重現文獻數據。各個部分的計算都要保證數據質量。比如算穩定狀態必須確保波函數穩定、確保無虛頻。雖然做波函數穩定性測試和振動分析會增加耗時,但必要時必須做,否則可能得到錯誤的結果而無法重復文獻。不要輕易使用比如Gaussian里opt=loose這種關鍵詞放寬收斂限,否則很可能收斂限太松導致某些情況對文獻數據重復性太差,尤其是此時做振動分析得到的頻率的準確度很可能很糟糕。用取消SCF收斂情況檢查的IOp(5/13=1)這種危險關鍵詞的時候必須謹慎檢查最終SCF收斂情況,千萬別最后收斂精度很爛卻直接使用其數據。再比如對于通過分子動力學計算物質平衡狀態屬性時,必須保證采樣充分使統計誤差足夠小。再比如考察某種磷脂膜體系的特征時,需要模擬時間足夠長以使得體系充分達到平衡,本身這類體系達到平衡所需的時間就偏長,動輒需要100 ns以上
? 沒恰當考慮對稱性問題。對于有對稱性的體系,在Gaussian等支持對稱性的量子化學程序里,要盡可能利用對稱性,這樣計算又好又快,內行的研究者的文章里對于能利用對稱性的情況幾乎都會利用。不利用對稱性甚至可能還會得到和文獻不符的結論,比如文獻報道某個體系是平面的,但你一開始擺的結構是彎曲的,由于優化的收斂不可能無窮精確,最后你得到的結構可能輕微偏離平面,與文獻結論不一致。如果體系本身沒有那么高對稱性,你一開始當成高對稱性結構來計算,最后可能錯誤地得到了高對稱性結構,也和文獻不符(這種情況只要做一下振動分析看有沒有虛頻便知)。
? 其它低級錯誤:單位轉換因子沒用對或者用的不準確(比如百毒搜出來的大量轉換因子都是錯的)、該做構型/構象搜索的情況沒做或者做得不當、該考慮構型/構象權重平均的情況沒考慮、優化表面吸附問題時把被吸附分子放得太遠導致還沒優化到吸附狀態就滿足了收斂判據、處理數據用的Excel表格或者腳本存在問題、科學計數法記錄的數據沒讀對(如漏掉了指數部分),等等
8 文獻自身有問題
千萬不要只懷疑自己而不懷疑文獻,盡信文獻不如無文獻,很多文獻里(包括IF很高的期刊的文章里)的數據是有錯誤的,甚至是非常明顯的錯誤,上一節提到的各種犯錯的例子也都出現在很多文獻里。比如《我對一篇存在大量錯誤的J.Mol.Model.期刊上的18碳環研究文章的comment》(http://www.shanxitv.org/584)里我就指出一篇文章里從頭到尾的一大堆錯誤,諸如作者計算C18的時候大概率由于用的是非平面的初始結構,導致優化出的C18不是精確平面的,然后他們發現C18的極小點結構竟然有ECD信號,明顯這是虛假的結果。
還有些文獻里對數據的解釋、標注是錯的,是他們對數據理解有問題。比如直接把HOMO、LUMO能量的負值說成是氧化、還原勢是很多涉及電化學的文章里常見的事,顯然你如果以正確的方式來算,也即計算溶液下的電極反應的自由能變,結果肯定和文獻對不上。再比如有不少文獻用的費米能級是錯的,對有gap的體系直接就把價帶頂當做費米能級,這明顯不符合正確的確定有限溫度下費米能級的方式(正確定義參看wiki相應條目和Multiwfn手冊3.300.9節)。
還有些文獻里的計算方式從描述上就知道是錯的。比如有的文獻寫G=Eele+ZPE-TS,有本科化學知識的人都知道這明擺著不對,H(T)和U(0)之間的差異上哪去了?就算是作為近似不考慮這部分、假設這部分在求差的時候能極大抵消,至少也應該把等號寫成約等號。這種明顯不合理的數據就別去重復了,非要重復的話那就暫時性降智故意用錯誤的公式。
很多文獻作者也對數據很不負責任。比如之前我在IF很高的文獻里看到補充材料中的Gaussian輸入文件里居然全帶著IOp(5/13=1),這文獻的數據的可靠性沒法令人不放心(雖然作者可能檢查了最終收斂情況,但誰也不敢說作者確實這么做了)。現在有很多無良代算機構,沒一丁點搞理論計算的人的基本操守,為了能給出令做實驗的人滿意的與實驗相符的計算數據來交差,極有可能在算不出期望的數據的情況下捏造假數據,這樣的數據更別指望能被別人重復出來了。甚至有的代算方連計算都不計算,直接憑空胡編亂造數據,建議讀者看看《談談我對計算化學代算的看法》(http://www.shanxitv.org/505)里提及的情況。
有很多文獻對計算的關鍵要點、直接影響數據可重復性的因素交代得非常粗糙、簡略、語焉不詳,甚至根本不提,這無疑給讀者帶來了很多誤解、給別人重復計算造成了障礙。重復這些文章的數據只能是考慮各種可能情況去試了。另外,還有可能文章里用的參數、設置本來就不慎寫錯了,作者寫的程序本身存在bug等等。
對于已經恰當考慮了前面說的所有因素,竭盡全力去重復文獻,但還是重復不出來(且確實是有不可忽視的差異而不是在復現精度上過度較真),如果沒有絕對必要去重復文獻,那就別去重復了,極有可能文獻的數據就是有問題的,或者沒交代關鍵性計算細節。這種情況只要你能保證自己的計算是合理的就夠了。但如果有特殊原因就是非要重復文獻不可,顯然該做的不是在思想家公社QQ群或者計算化學公社論壇(http://bbs.keinsci.com)等公開場所提問,因為找誰都不如直接找作者,世界上還有誰比作者更清楚數據是怎么來的的人么?世界上還有誰比作者更有回復你的義務?發郵件給通訊作者,向作者索要相應數據的輸入輸出文件,或者向作者提供你復現文獻計算的輸入輸出文件問作者為什么沒重復出來即可。當然很有可能一直沒收到作者的回復,可能性有這些:
(1)作者看漏了你的郵件,或者郵件被誤歸入垃圾郵件,或者正忙著什么事沒來及回復你結果后來又忘了。可以過一個禮拜(且可以換個郵箱)再發一次試試。如果通訊作者有多個,也可以給另外的人發
(2)措辭不當,不夠禮貌和誠懇,而作者脾氣又大或者又比較忙,又覺得回復你也沒什么好處,就不回了。可以過一陣重新措辭再發一次。為了讓作者有動力花時間給你回復,最好表示你會在未來的文章中會引用他的文獻。
(3)文獻中的數據是作者找別人代算的,代算方又是非常不負責任的,相關文件也不提供、計算細節也不交代清楚,甚至代算之后就再也聯系不上了,因而作者也無能為力。
(4)做計算的是學生,學生畢業后找不到人了,導師又不清楚計算細節、沒原始文件。
(5)文獻中的計算本身就有嚴重錯誤或是假數據,可能收到你的郵件后作者才意識到,又或者可能之前就已經明知道用的是假數據,總之都不希望你知道他的數據存在問題,免得面子上掛不住,甚至怕文章最后被撤稿。
8字形雙環分子對18碳環的獨特吸附行為的量子化學、波函數分析與分子動力學研究
Quantum chemistry, wavefunction analysis and molecular dynamics study of the unique adsorption behavior of 8-shaped bicyclic molecule to cyclo[18]carbon
文/Sobereva@北京科音 2023-Jun-30
0 前言
18碳環于2019年首次在凝聚相實驗中被觀測到后,其獨特的幾何和電子結構引發了學術界的巨大關注,筆者對18碳環及其衍生物做了大量、系統的理論研究工作,論文匯總以及深入淺出的介紹文章見http://www.shanxitv.org/carbon_ring.html。2022年Angew. Chem., 134, e202113334 (2022)新合成出一種具有兩個大環的整體看上去像8字形的分子,每個大環都由一串苯環相連構成,此體系以下簡稱oligoparaphenylene (OPP),如下圖最下側的結構所示。此文實驗發現OPP可以穩定結合兩個C60或C70富勒烯。另外,由下圖所示意的,11個苯環構成的環狀分子[11]CPP也已知可以吸附C70。
考慮到18碳環的直徑和C70富勒烯相近(如上圖所標注的),OPP是否也有可能吸附18碳環分子來實現18碳環的富集?此外,18碳環本身不穩定、易反應,若利用OPP吸附來保護住的話,還有可能實現18碳環的穩定化,無疑這很有實際意義。受到這個想法的啟發,筆者和江蘇科技大學的劉澤玉等人通過量子化學、波函數分析和分子動力學對OPP吸附18碳環的可能性從各個角度做了全面深入的探究,并在近期發表了通訊文章,非常歡迎讀者們閱讀和引用:
Molecular assembly with a figure-of-eight nanohoop as a strategy for the collection and stabilization of cyclo[18]carbon, Phys. Chem. Chem. Phys., 25, 16707 (2023) https://doi.org/10.1039/d3cp01896b
在下文中,筆者將對這篇研究工作的主要內容和研究思想進行深入淺出的介紹,還將同時還做許多擴展討論和細節說明,圖片來自于上文以及其補充材料(有的圖略有差異,版本不同)。希望本研究能對讀者研究類似問題有所啟發、將本文的研究手段應用于相似問題的研究上。如果大家不了解18碳環的基本特征的話,建議閱讀《談談18碳環的幾何結構和電子結構》(http://www.shanxitv.org/515)和筆者之前發表的Carbon, 165, 468 (2020) https://doi.org/10.1016/j.carbon.2020.04.099中關于18碳環電子結構的討論以了解這方面的背景知識。
1 吸附形成的結構
文中首先研究OPP吸附一個和兩個18碳環后的結構。幾何優化和振動分析使用Gaussian 16在wB97XD泛函下進行,因為在Carbon, 165, 468 (2020)文中證明了此泛函可以很好地描述18碳環的結構,而且此泛函又可以合理地描述弱相互作用,故拿來優化2C18@OPP復合物很適合。2C18@OPP多達260個原子,而優化+振動分析任務又很昂貴,因此這個環節用的基組不能太貴,文中對包含224個原子的OPP部分使用6-31G*,對更重要但占較小部分的C18使用更大的6-311G*。順帶一提,對C18不能圖便宜也用6-31G*,因為如《我對一篇存在大量錯誤的J.Mol.Model.期刊上的18碳環研究文章的comment》(http://www.shanxitv.org/584)里介紹的論文所示,6-31G*都不足以合理描述C18的幾何結構。優化后的帶一個和兩個18碳環的OPP結構如下所示
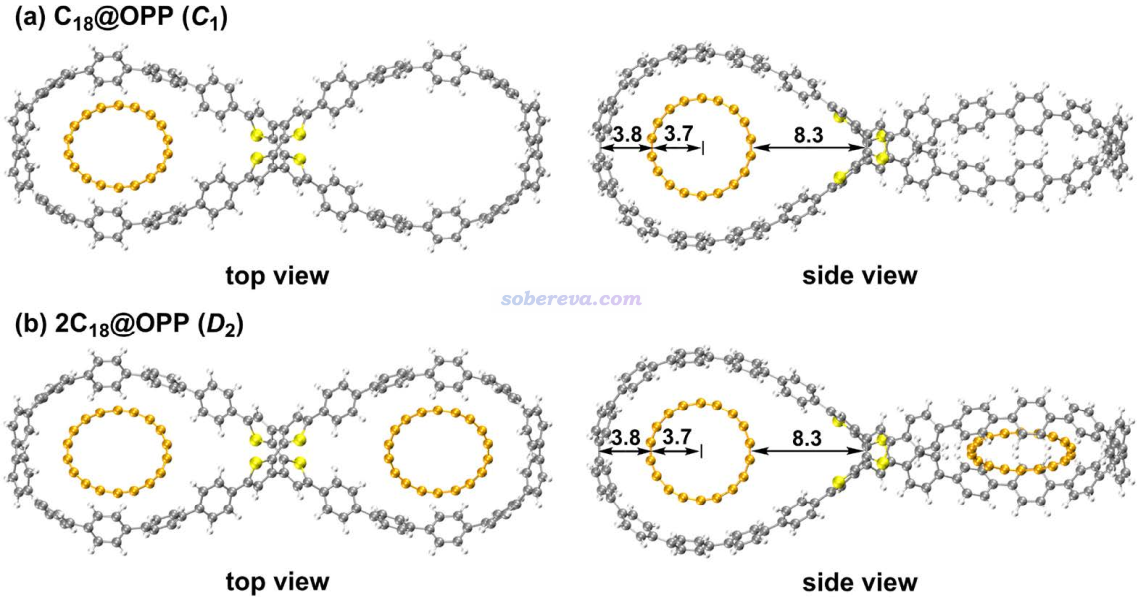
從上圖可見由于尺寸匹配,18碳環能非常理想地嵌入進OPP的大環中,C18環平面和大環的平面平行。此外,C18的吸附基本不改變大環原有的形狀。
2 吸附的熱力學
為了從熱力學角度探究吸附的可行性,文中對OPP吸附一個18碳環的結合能ΔG進行了計算,并且為了更進一步探究焓和熵所產生的貢獻,根據ΔG=ΔH-TΔS,文中將焓變ΔH(結合焓)和熵增對結合自由能的貢獻(-TΔS)項分別給了出來。同時為了考察溫度對吸附的影響,文中利用《使用Shermo結合量子化學程序方便地計算分子的各種熱力學數據》(http://www.shanxitv.org/552)中介紹的非常方便的Shermo程序一次性得到了各個溫度下的熱力學量,從而繪制了下圖。
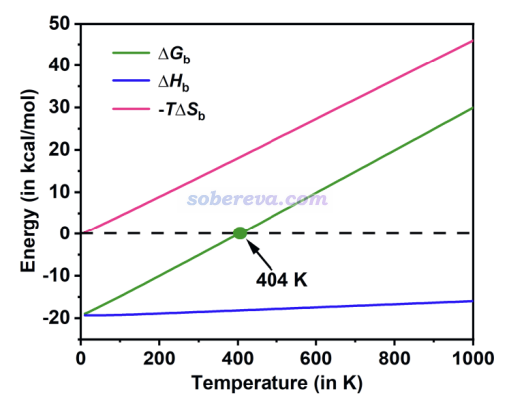
從上圖可見,結合焓受溫度影響相對不大,是個明顯的負值,這是C18能夠與OPP結合的驅動力。而分子間結合會造成熵的顯著降低,因此-TΔS總為正,且溫度越高這項越正,越不利于結合,是C18與OPP結合的阻礙。這兩部分共同決定結合自由能。在404 K以下,結合自由能為負,C18能夠與OPP結合,而在此溫度以上則熱力學上無法結合;即便之前C18已經吸附了,也會發生脫附。由于這一點,可以通過溫度來實現OPP對C18的可控的吸附和釋放。即低溫下吸附,高溫下釋放。
以上數據的計算有兩點值得說明:
(1)文中使用Shermo基于Grimme提出的準RRHO模型計算熱力學校正量中的熵,這一點非常重要,Gaussian用的RRHO模型會嚴重高估諸如C18@OPP這種含有很低頻體系的熵。所以哪怕不靠Shermo考察熱力學量隨溫度的影響,也不要直接用Gaussian給出的熵和自由能熱校正量而應當用Shermo來計算它們。
(2)為了準確地計算結合自由能、結合焓,以上數據中涉及的電子能量是使用ORCA在wB97M-V/def2-QZVPP下開著RIJCOSX計算的,這個級別算弱相互作用相當準確,而且是算當前這種較大體系最理想的選擇。同時由于wB97M-V是長程100% HF成份的長程校正泛函,自相互作用誤差較小,因此可以和具有同等特征的wB97XD一樣正確描述18碳環。由于def2-QZVPP很昂貴,故直接算C18@OPP這樣兩百多原子的體系算不動,因此文中使用了半邊模型, 如下所示,是在C18@OPP結構基礎上把和吸附無關的那一頭的大環去掉并用氫封閉的結構。由于另一頭的大環距離吸附的C18甚遠,因此這種處理不會影響計算結合能的精度。
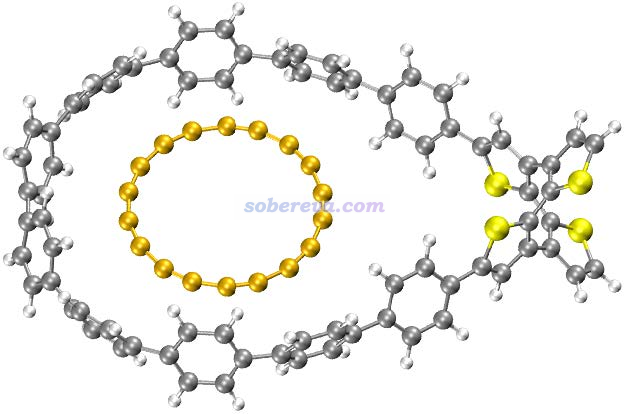
3 吸附作用的本質
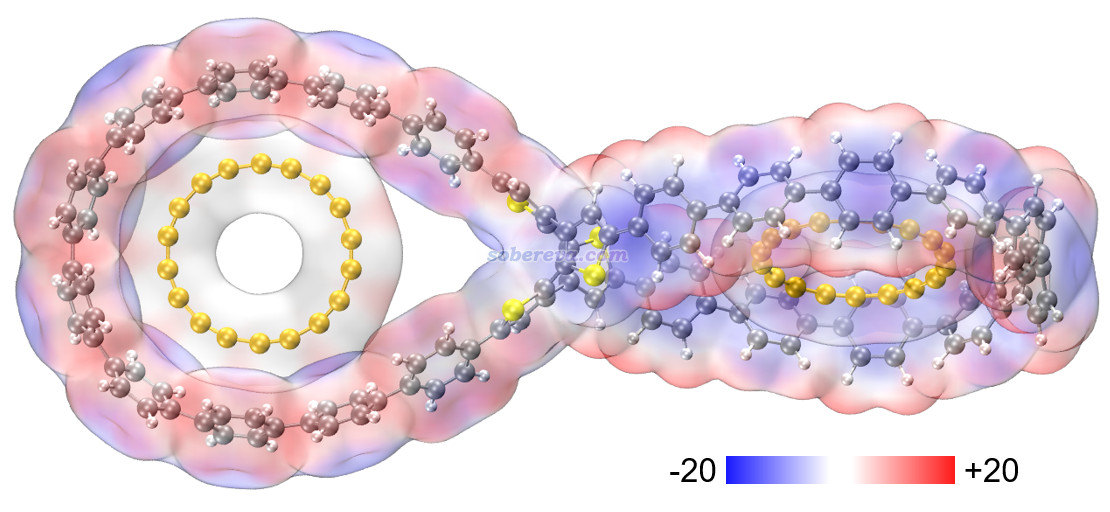
什么樣的機制導致了OPP能夠吸附C18?為了考察這一點,本文繪制了如今已被廣泛使用的筆者所推廣的分子表面靜電勢穿透圖,利用Multiwfn結合VMD可以按照《使用Multiwfn+VMD快速地繪制靜電勢著色的分子范德華表面圖和分子間穿透圖(含視頻演示)》(http://www.shanxitv.org/443)中所示的過程非常容易地繪制,結果如下,是在wB97XD/6-311G*級別繪制的,色彩刻度條單位為kcal/mol。由圖可見,18碳環與OPP的范德華表面存在一定程度的穿透,這是兩個分子結合后在平衡結構下會出現的典型特征。此圖也體現出18碳環的形狀著實和OPP的大環吻合得很好,匹配得很完美。由圖還可以看出,18碳環表面的靜電勢非常小,這點在《全面探究18碳環獨特的分子間相互作用與pi-pi堆積特征》(http://www.shanxitv.org/572)介紹的文章中我也專門指出過。OPP表面靜電勢雖然比C18更大,但也僅在較小的數值區間內。通過表面靜電勢的特征就可以看出C18與OPP之間的靜電作用是甚微的,不可能對結合起主導作用。
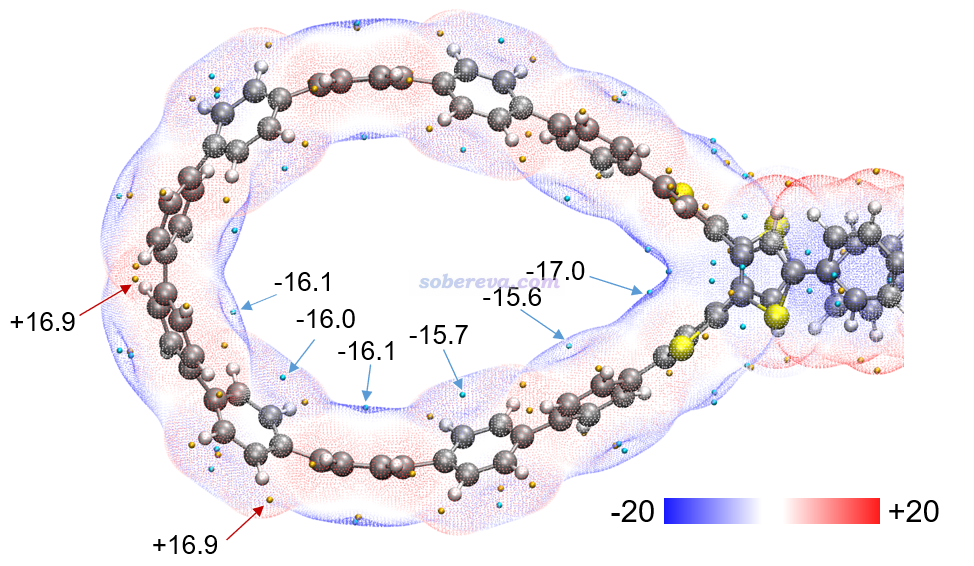
下圖是按http://www.shanxitv.org/443博文說的做法用Multiwfn+VMD繪制的OPP分子表面極值點數值(kcal/mol),可以把OPP表面靜電勢分布情況展現得更清楚。青色小球是表面靜電勢極小點,橙色是極大點。
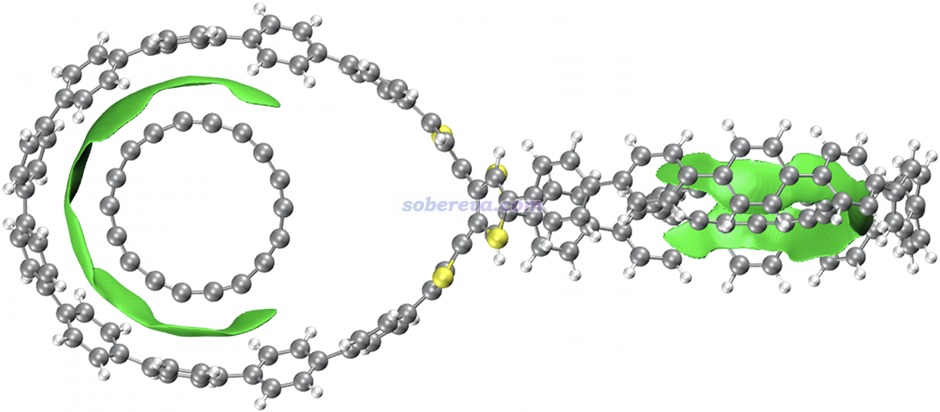
然后我們再關注OPP與18碳環之間可能存在的范德華作用。筆者提出的范德華勢是研究這種問題絕佳的手段,介紹見《談談范德華勢以及在Multiwfn中的計算、分析和繪制》(http://www.shanxitv.org/551)、使用《Multiwfn對靜電勢和范德華勢做拓撲分析精確得到極小點位置和數值》(http://www.shanxitv.org/645)。以碳原子作為探針原子(對應18碳環上的原子),OPP的-1.2 kcal/mol的范德華勢等值面如下圖所示。可見OPP產生的范德華勢最負的區域,也即它的范德華作用對碳原子吸引最強的部分,正好與C18原子在吸附后出現的區域相重疊。這充分體現出OPP對18碳環必定有顯著的范德華吸引作用,這應當是OPP對18碳環吸附的最主要本質。當前體系是范德華勢分析的很好的應用實例。

文中進一步使用Multiwfn結合VMD使用筆者提出的IGMH方法展現了OPP與18碳環的相互作用,對2C18@OPP繪制的0.002 a.u.的分子間的IGMH等值面如下圖所示。IGMH的介紹見《使用Multiwfn做IGMH分析非常清晰直觀地展現化學體系中的相互作用》(http://www.shanxitv.org/621)和《一篇最全面介紹各種弱相互作用可視化分析方法的文章已發表!》(http://www.shanxitv.org/667)。IGMH的等值面非常清晰地把OPP與18碳環之間的相互作用展現了出來,而且其顏色完全為綠色,說明作用區域電子密度很低,而且等值面又很扁且廣闊,這明顯是色散吸引主導的相互作用的特征。再加上18碳環具有in-plane pi電子,在吸附進OPP后正好與OPP大環的苯環的pi電子分布區域對著,因此可以明確指出18碳環與OPP與形成了顯著的pi-pi堆積作用。值得強調的是,靠in-plane電子形成pi-pi堆積,這是碳環體系所獨有的特征,非常具有個性。
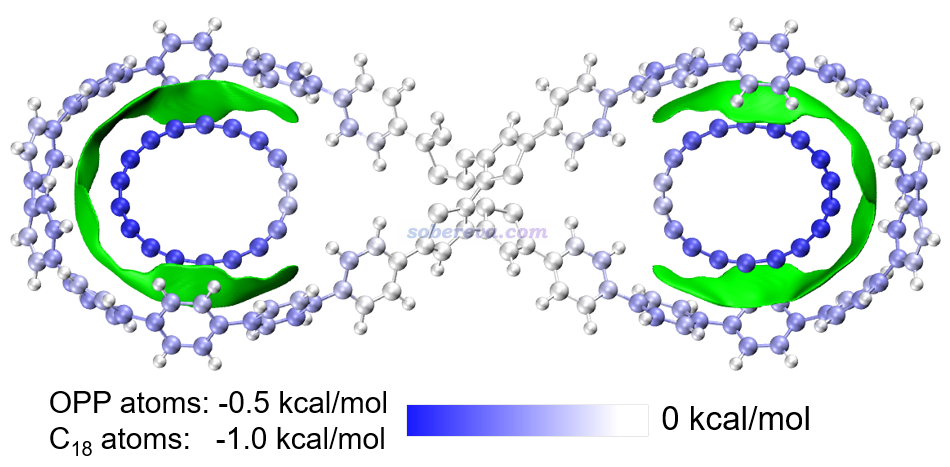
本文還使用筆者提出的基于力場的能量分解方法EDA-FF考察了各個原子對C18與OPP結合產生的貢獻。EDA-FF的介紹見《使用Multiwfn做基于分子力場的能量分解分析》(http://www.shanxitv.org/442)。此文的EDA-FF完全基于GAFF力場實現。由于C18的原子電荷均為0,所以此分析中沒有靜電作用項而只有范德華作用部分。EDA-FF計算的平衡結構下C18與OPP的相互作用能為-26.0 kcal/mol,這與高精度wB97M-V/def2-QZVPP計算的-20.3 kcal/mol相差并不很大,因此EDA-FF分析結果完全能說明問題。在上圖中,各個原子對C18-OPP結合能的貢獻通過原子著色予以了展示。由于C18和OPP上的原子對相互作用貢獻的數量級差異較明顯,因此用了不同的色彩刻度。由上圖可清楚看出,C18上每個原子對相互作用能的貢獻在-0.7至-1.0 kcal/mol的范圍,離OPP中心(pi-linker部分)越遠的原子由于與OPP大環上的原子帖得越近,因而貢獻也越大。相應地,OPP大環上的原子與C18離得越近的那些原子對相互作用貢獻也越大。而在OPP兩個大環之間的pi-linker附近的原子則對結合的貢獻基本為0。通過此例可見通過EDA-FF能非常清楚地展現出各個原子對結合所起到的作用,極具實用性。
4 吸附的分子動力學
為了準確地從動態角度考察完整的吸附過程,此文使用GROMACS程序基于經典力場做了吸附過程的分子動力學模擬。在300K下C18進入OPP的總共2000 ps的模擬軌跡的完整視頻可在此觀看,情況一目了然(其中18碳環的一個原子用紅色高亮以便于觀察18碳環的旋轉情況):http://www.shanxitv.org/attach/674/C18_enter_OPP_2ns_300K.mp4
下面說明一下研究C18進入過程的具體細節。
由于OPP是結構很特殊的體系,絕對不能直接用諸如GAFF力場去模擬OPP,否則實測結構會嚴重變形,兩個大環區域會幾乎成為嚴格的圓形而不是液滴狀。為了能通過力場合理地描述OPP,就必須利用筆者開發的sobtop程序(http://www.shanxitv.org/soft/Sobtop)在拓撲文件構建方面提供的靈活性,即允許一部分用剛性參數,一部分用柔性參數。本研究將兩個大環之間的相對剛性的pi-linker部分用量子化學計算的Hessian矩陣通過mSeminario方法計算出的力常數和平衡參數來描述,而大環部分則用GAFF力場參數描述,這樣可以允許其中的苯環部分發生應有的旋轉。另外,模擬C18用的C-C鍵的參數也都是sobtop基于Hessian矩陣嚴格算出來的。實測發現,使用這種方式構建的拓撲文件通過GROMACS做能量極小化得到的C18@OPP構型與量子化學優化得到的相當吻合,見下圖的對比,藍色是wB97XD優化出來的,棕色是基于分子力場做能量極小化得到的。
基于以上方式得到的參數,在模擬時,筆者將C18@OPP四周擴了一定區域設立了一個大的周期性盒子,將兩個18碳環隨機插入在其中,然后在300 K下進行了模擬。下圖將碳環進入過程的一些關鍵時間區間通過多幀疊加方式予以了展現,每個時間區間內碳環按照白到黃的方式著色來清楚區分不同時刻所在的位置,圖像通過VMD繪制。下面三幅子圖只顯示了感興趣的OPP右半邊的情況。第一個C18在模擬才到200 ps時就已經進入OPP了,下圖就只關注進入得晚一些的第2個C18的情況。由圖可見,852-884 ps時間內C18從OPP外部擦著它的外沿順利滑入大環空腔,而之前就已經進入另一側大環中的C18還在原處晃悠沒受什么影響。在884-1448 ps期間,剛進入的C18自發貼到大環的內壁傾斜地呆了一陣子。在1448-1460 ps期間,原本貼著大環內壁的亞穩的吸附構型發生了改變,C18自發變得平行于大環。在1460ps到模擬結束(2000 ps)期間內,在大環里躺平的C18就一直穩定地呆在那了,也說明這是在300 K下能夠穩定存在的吸附結構。
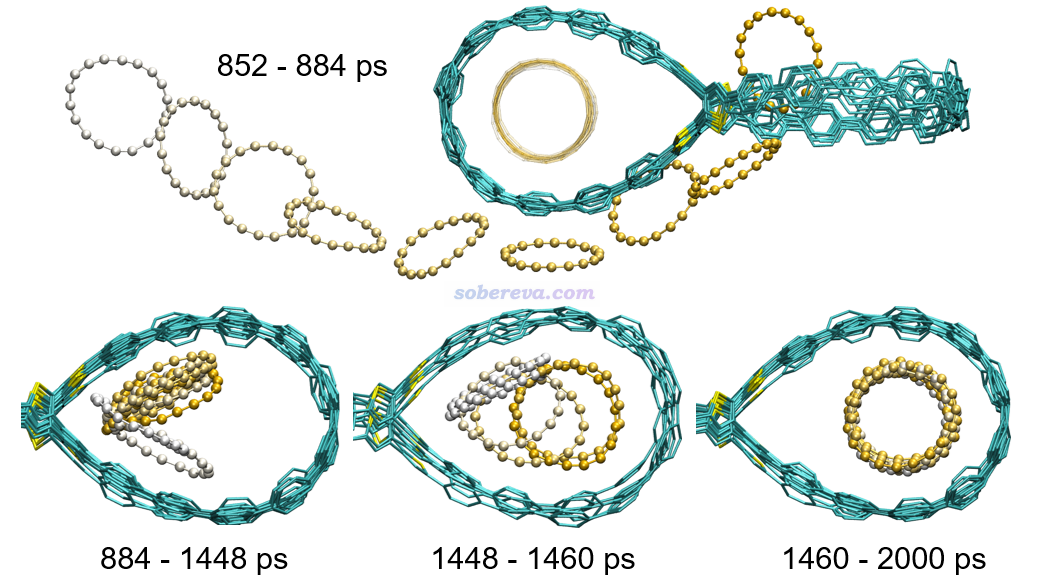
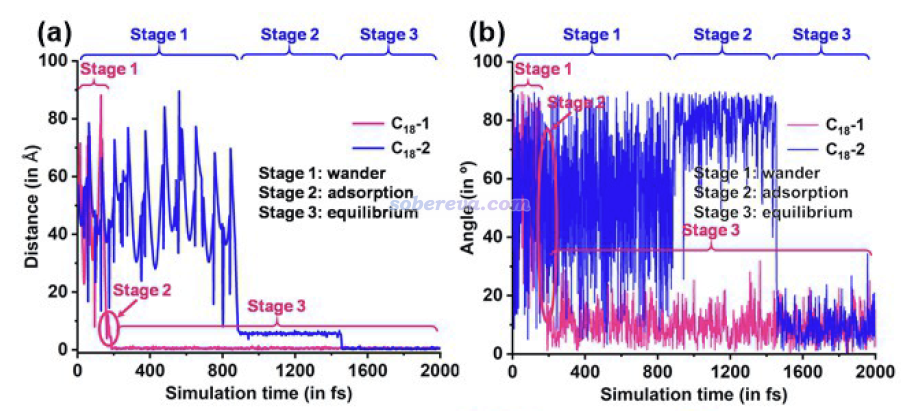
下圖還對C18進入過程做了細致的幾何參數分析,包括C18與OPP大環的中心之間的距離,即下圖(a),以及C18與OPP大環之間的夾角,即下圖(b)。圖中對兩個C18的情況都做了統計,分別是紅線和藍線。結合這些幾何參數的變化和軌跡,文中將OPP吸附C18的過程分為三個階段:(1)wander,即C18在OPP周圍漫游的過程 (2)adsorption,即C18進入OPP并處于亞穩態構型的過程 (3)equilibrium,即C18在OPP大環中處于完全平衡狀態。拿第2個C18為例,下圖可見當它處于真空區中游蕩而沒撞上OPP的時間內,它與OPP大環的距離和夾角都在反復大幅波動,在剛吸附到大環里成為亞穩態時,其夾角和中心間的距離和最終穩定狀態都存在一定差異。第1個C18進入過程也是分為這么三個階段,只不過恰好階段2非常短暫,即這個C18剛吸附進大環后迅速就躺平達到穩定構型了。這些階段出現的時刻、長短,都有一定隨機性,直接受到初始結構里C18所處的位置、初速度的影響。筆者通過大量重復模擬,都驗證了以上描述的C18進入OPP的過程是普遍現象。
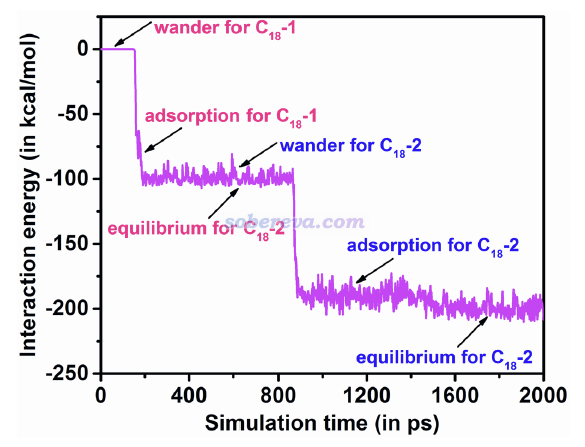
下圖是模擬過程中C18與OPP的相互作用能的變化,可見吸附時相互作用能有大幅增加(變得更負),并且從C18在大環里傾斜的亞穩態構型變成躺平的穩定構型過程中相互作用能又有所增加。明顯體現出這些過程都是能量降低所驅動的。
5 吸附受電子激發的影響
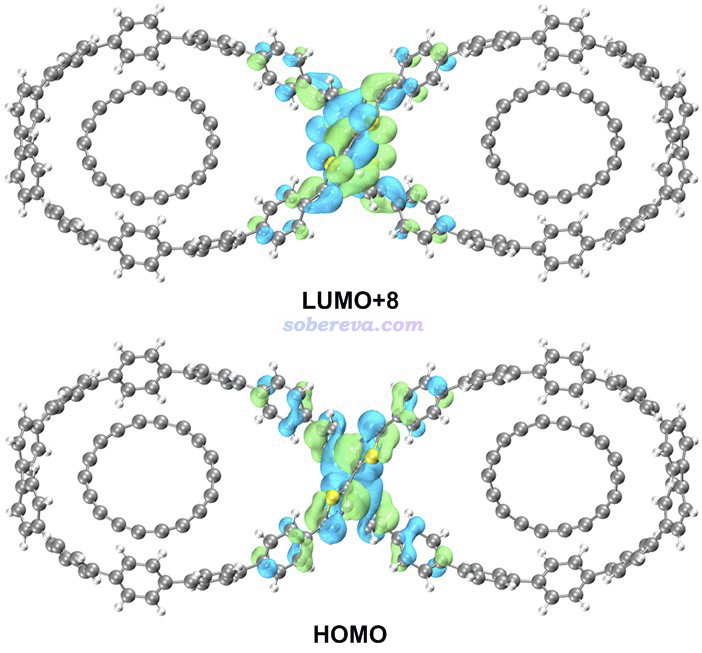
本文研究的OPP的位于中央的pi-linker已知在激發態下具有Baird芳香性,因此電子激發會導致結構發生明顯的變形(開口更大、更接近平面),無疑這可能明顯影響大環的形狀以及對C18的吸附行為。為了探究這一點,本文對OPP的最低單重激發態S1使用TDDFT結合wB97XD泛函做了幾何優化,S1結構如下圖粉色所示,基態S0結構如下圖藍色所示。可見確實電子激發明顯影響了OPP的結構,令pi-linker開口更大了、大環部分變得更圓了。
電子激發計算發現S0-S1躍遷由HOMO到LUMO+8的躍遷所主導,貢獻達到86.8%,這兩個軌道如下圖所示,通過Multiwfn結合VMD按照《用VMD繪制藝術級軌道等值面圖的方法(含演示視頻)》(http://www.shanxitv.org/449)介紹的方法繪制。可見都在pi-linker部分,是高度定域化的激發,而大環部分幾乎沒受影響。這也體現出為什么電子激發能對pi-linker的結構有顯著影響。
本文還對2C18@OPP復合物用TDDFT做了幾何優化,之后計算了結合能。S0態的結合能為-18.8 kcal/mol,而S1態為-17.1 kcal/mol,說明S1態下OPP對18碳環的吸附變弱了。雖然結合能的改變幅度不算很大,但畢竟吸附的平衡常數受結合自由能影響很大,因此在OPP能夠吸附C18的臨界溫度(前述的404 K)附近,OPP對C18的吸附在一定程度上會受到光控制。
對S1態2C18@OPP復合物,文中也用IGMH方法直觀展現了相互作用情況,和前面S0態的圖一樣也是用的0.002 a.u.繪制。相比之下,可以看出在S1態下等值面往OPP pi-linker部分的延伸程度有所減小,體現出S1態下由于pi-linker開口更大,使得靠近pi-linker的大環原子與C18之間的相互作用明顯變弱,這解釋了為什么S1態下OPP與C18的結合能的大小變小了。
6 吸附對紅外和UV-Vis光譜的影響
文中還考察了OPP吸附18碳環如何影響紅外和UV-Vis光譜,如下圖所示。可見OPP吸附一個18碳環后會在379.6和2122.0 cm-1處出現新的峰,前者對應碳環的C-C-C鍵角彎曲振動,后者對應于C-C鍵伸縮振動。而再吸附第二個C18之后,雖然峰的波數沒有進一步變化,但18碳環所引入的峰明顯變得更強了。關于碳環的振動特征,強烈建議閱讀《揭示各種新奇的碳環體系的振動特征》(http://www.shanxitv.org/578)里的介紹。
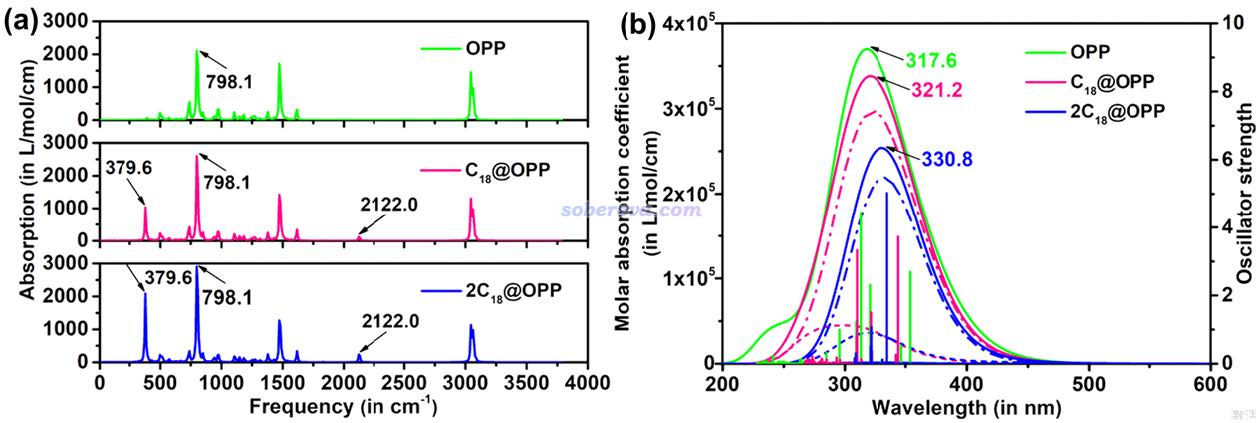
從上圖的UV-Vis吸收光譜中可以看到,OPP吸附越多的C18分子,吸收峰越紅移,吸收強度越低。
根據以上所示的OPP吸附不同數目的C18所對應的明顯不同的紅外和UV-Vis光譜,實驗化學家可以通過光譜技術檢測C18是否吸附到了OPP,以及吸附的量如何。
7 總結
本文介紹了近來筆者在Phys. Chem. Chem. Phys., 25, 16707 (2023)上發表的很有意思的具有8字形雙環結構的OPP與新穎獨特的18碳環相吸附形成1:2 主-客體復合物的研究。文中利用量子化學計算、波函數分析和分子動力學模擬,從各個角度全面揭示了吸附的本質和特點,還考察了光激發對吸附的影響。本文也是波函數分析與Multiwfn程序研究實際問題的很好范例。相信本文的研究工作的思想和手段能對其他人通過理論化學研究吸附問題產生啟發作用。
另外,如果你對pi-pi研究感興趣,強烈建議閱讀《談談pi-pi相互作用》(http://www.shanxitv.org/737)。
]]>Introduction to the mol2 format for recording chemical structures
文/Sobereva@北京科音 2022-Dec-31
1 mol2文件簡介
mol2文件是計算化學領域非常常用的記錄分子結構的格式,被很多程序所支持和利用。例如VMD、GaussView、Chem3D、OpenBabel、AmberTools里的Antechamber等程序都可以導出mol2文件,筆者開發的Multiwfn(http://www.shanxitv.org/multiwfn)可以基于mol2文件計算EEM原子電荷,筆者開發的Sobtop(http://www.shanxitv.org/soft/Sobtop)可以基于mol2文件產生GROMACS的拓撲文件,等等。
相對于非常常見的在《談談記錄化學體系結構的xyz文件》(http://www.shanxitv.org/477)中介紹的xyz格式,mol2格式關鍵優點在于可以記錄成鍵信息,即誰與誰成什么形式的鍵,這對于判斷原子所處的化學環境非常重要,比如Sobtop需要有這樣的成鍵信息才能自動指認GAFF原子類型,Multiwfn計算EEM原子電荷時需要有這樣的信息才能判斷各個原子要用的EEM參數。另外mol2文件還可以記錄其它諸多信息(距離約束、可旋轉的鍵、原子類型和電荷等等),對于分子模擬、QSAR、化學信息學等一些方面有特殊的意義。
mol2格式略微復雜,不同程序產生的mol2文件有所出入,有的程序產生的mol2文件還不規矩,導致經常有人由于用的mol2文件有問題而無法用Sobtop和Multiwfn等程序正常處理,甚至導致程序崩潰。我遂覺得有必要寫一篇文章介紹一下mol2格式,便于讀者了解怎么讀取mol2文件的信息、判斷自己手頭的mol2文件是否規范,以及拿到不標準的mol2文件時怎么修改。
mol2文件是文本格式,包含大量的字段,每個字段各有各的用處和定義規范。mol2文件的詳細說明可以下載此文檔查看:http://www.shanxitv.org/attach/655/Tripos_Mol2_File_Format.pdf。這些字段并不是全都需要出現的,常見的字段只有幾個而已,每個字段涉及的信息中往往也只有其中少部分會經常涉及到,將在下文進行介紹,若想更全面詳細了解mol2格式可閱讀上述文檔,共54頁。
本文提到的程序的版本是VMD 1.9.3、Multiwfn 3.8(dev, 2022-Dec-18)、Sobtop 1.0(dev3.1)、GaussView 6.0.16、OpenBabel 3.1.1。其它版本可能與本文相同也可能不同。
2 mol2文件的例子和解讀
OpenBabel程序產生的mol2格式相對來說是屬于比較規矩的,這里結合OpenBabel程序產生的苯甲醛的mol2文件的內容進行講解。我先用一個可視化程序畫了一個苯甲醛的結構,保存為了benzaldehyde.pdb文件,然后用obabel benzaldehyde.pdb -O benzaldehyde.mol2命令用OpenBabel把pdb格式轉成了mol2格式的benzaldehyde.mol2文件,其內容如下,GaussView載入此文件后顯示的結構圖也給出了以便于對照
@<TRIPOS>MOLECULE
benzaldehyde.pdb
14 14 0 0 0
SMALL
GASTEIGER
@<TRIPOS>ATOM
1 C 1.9920 0.4700 -0.0000 C.2 0 UNK0 0.1502
2 C 0.5340 0.2150 -0.0000 C.ar 0 UNK0 0.0142
3 C -0.3610 1.2920 -0.0000 C.ar 0 UNK0 -0.0515
4 C -1.7360 1.0600 0.0000 C.ar 0 UNK0 -0.0611
5 C -2.2160 -0.2520 0.0000 C.ar 0 UNK0 -0.0617
6 C -1.3250 -1.3310 -0.0000 C.ar 0 UNK0 -0.0611
7 C 0.0460 -1.1010 -0.0000 C.ar 0 UNK0 -0.0515
8 O 2.8450 -0.3960 0.0000 O.2 0 UNK0 -0.2957
9 H 2.2730 1.5470 0.0000 H 0 UNK0 0.1081
10 H 0.0250 2.3090 -0.0000 H 0 UNK0 0.0624
11 H -2.4300 1.8950 0.0000 H 0 UNK0 0.0618
12 H -3.2860 -0.4350 0.0000 H 0 UNK0 0.0618
13 H -1.7060 -2.3480 -0.0000 H 0 UNK0 0.0618
14 H 0.7610 -1.9170 -0.0000 H 0 UNK0 0.0624
@<TRIPOS>BOND
1 1 2 1
2 1 8 2
3 1 9 1
4 2 3 ar
5 2 7 ar
6 3 4 ar
7 3 10 1
8 4 5 ar
9 4 11 1
10 5 6 ar
11 5 12 1
12 6 7 ar
13 6 13 1
14 7 14 1
首先要知道mol2文件里以#作為第一列的是注釋行,空行也被完全無視。mol2文件是自由格式,因此空格數目完全隨意。
第一列以@開頭的叫做字段,從上面的benzaldehyde.mol2可見,當前文件有@<TRIPOS>MOLECULE、@<TRIPOS>ATOM、@<TRIPOS>BOND三個字段。一般來說這三個字段都是必須出現的,一起提供了描述一個分子最起碼的信息。
2.1 MOLECULE字段
@<TRIPOS>MOLECULE字段記錄了體系的基本信息,包括:
第1行:體系的名字。可見OpenBabel把轉換出mol2文件的源文件的名字benzaldehyde.pdb當做了當前體系的名字
第2行:五個數字分別是體系中的原子數、化學鍵數、子結構數、特征數、set數。對于單純記錄體系結構信息,只要提供前兩者就夠了,后三個可以省略。所謂的子結構是指體系中的一個部分,比如每個分子、每個殘基、蛋白質的每條鏈等等都可以在@<TRIPOS>SUBSTRUCTURE字段里定義為一個子結構。所謂的set是指基于體系中的一些原子/鍵/子結構根據特定規則和需要定義的集合,可以在@<TRIPOS>SET里具體定義。
第3行:體系的類型。可以為SMALL(小分子)、BIOPOLYMER、PROTEIN、NUCLEIC_ACID、SACCHARIDE
第4行:原子電荷。如果mol2文件沒記錄原子電荷信息這里就為NO_CHARGES。而在產生當前benzaldehyde.mol2文件的時候OpenBabel自動計算了Gasteiger電荷,因此此處寫的是GASTEIGER。還可以為MULLIKEN_CHARGES(Mulliken電荷)、MMFF94_CHARGES(MMFF94力場定義的電荷)等等,不同種類電荷都有固定名字。如果記錄的原子電荷是比如Multiwfn算的ADCH、RESP、1.2*CM5等電荷,在mol2格式規范中沒有對應的名字,則這里應當寫USER_CHARGES。
2.2 ATOM字段
@<TRIPOS>ATOM字段每一行定義一個原子的信息,每一列記錄的信息為:
(1)原子序號(整數)
(2)原子名(字符串)
(3)X坐標(埃)
(4)Y坐標(埃)
(5)Z坐標(埃)
(6)原子類型(atom type。字符串)
(7)原子所屬的子結構序號(整數),可省略
(8)原子所述的子結構名字(字符串),可省略
(9)原子電荷(浮點數),可省略
原子名部分可以為比如C2、H4等等,完全隨意。記錄生物分子結構時通常用IUPAC定義的各種殘基中的原子名。
原子類型部分可以記錄做分子模擬用的力場中此原子實際對應的原子類型。mol2格式自己也有一套原子類型定義,見前述的Tripos_Mol2_File_Format.pdf文檔的末尾,比如sp3雜化的碳的原子類型是C.3,C.ar代表芳香碳,Any代表任意,Hal泛指鹵素,Cl代表氯,Ca代表鈣,H代表氫,H.spc特指SPC水模型的氫,LP代表孤對電子(lone pair),Du代表虛原子(dummy),等等。
一定要特別注意,mol2格式雖然定義了一大堆字段,但(居然)沒有一個地方是專門用來記錄元素的,這在我來看是mol2格式的嚴重不足!!!mol2記錄的原子名和原子類型信息可以與元素名相同也可以不同,不同程序產生的mol2文件的情況各有不同。例如如此例可見,OpenBabel產生的這個mol2文件里原子名恰等于元素名,原子類型是根據mol2格式自己定義的原子類型指認的。而在GaussView產生的mol2文件中,原子名是給元素名后面加了數字(因此不會有重名的原子),而原子類型恰等于元素名。由于情況混亂,所以一個程序在讀取mol2文件的時候并沒有嚴格的辦法能準確判斷元素,只能靠猜。Multiwfn和Sobtop在讀取mol2文件時是根據原子類型的字符串判斷元素的:如果字符串中沒有.,就直接將之當做元素名來判斷元素;如果有.,比如是C.3,就把.前面的內容當做元素名判斷元素。因此,讀者應該知道Multiwfn和Sobtop沒判斷對元素時該怎么辦了,最簡單的做法就是手動修改mol2文件以讓@<TRIPOS>ATOM字段每一行的第6列對應元素名。
由于子結構信息在原子電荷前面,因此即便你不想定義原子所屬的子結構信息而只想定義原子電荷,也必須隨便寫上子結構序號和子結構名字來占位,比如此例用0 UNK0來占位。
2.3 BOND字段
@<TRIPOS>BOND字段每一行定義一個鍵的信息,其每一列記錄的信息為:
(1)鍵的序號(整數)
(2)第1個原子的序號
(3)第2個原子的序號
(4)鍵的類型
鍵的類型有以下這些
? 1 = 單鍵
? 2 = 雙鍵
? 3 = 三鍵
? am = 酰胺的N-C鍵(這種鍵有一定pi共軛作用,這是為什么mol2格式里特意用am來與單鍵區分)
? ar = 芳香環(aromatic)上的鍵,以下簡稱芳香鍵
? du = 虛鍵
? un = 未知/無法判斷
? nc = 不相連(倆原子不成鍵就沒必要在BOND字段出現,但可以靠nc強調某兩個原子間就是沒成鍵)
絕大多數程序產生的mol2文件里沒有du、un、nc。
有的程序產生的鍵的類型名不規矩。比如GaussView對于芳香環上的鍵(具體來說,是圖形窗口里看到一個實線+一個虛線的那種鍵)用的類型是Ar,但按照mol2規范應當是ar,因此這會導致一些程序無法識別(而Sobtop在讀取時已經考慮到了GaussView的這個bug,因此用戶不用自己做替換)。GaussView還自行給mol2格式做了擴展,把圖形窗口里看到是一個虛鍵的那種鍵記錄為Wk代表Weak,而這可能導致很多程序無法正常識別和載入。
不同程序對成鍵的指認也往往有很大不同。比如甲酰胺,Avogadro產生的它的mol2里把N-C鍵記錄為am,嚴格符合mol2格式的要求。而GaussView則無法將之記錄為am,而是可能記錄為單鍵也可能記錄為Ar(取決于當前圖形窗口里顯示的成鍵方式)。另外,我之前在《談談原子間是否成鍵的判斷問題》(http://www.shanxitv.org/414)中說過GaussView是根據原子半徑和原子間距離判斷成鍵形式的,導致很有可能判斷出的成鍵方式很不“經典”,甚至很違背化學常識,比如可能顯示一個碳原子連著一個雙鍵和兩個單+虛鍵。而如果把結構保存成pdb然后再用OpenBabel轉成mol2格式,則成鍵方式就很經典了,因為OpenBabel能夠自動讓成鍵方式滿足經典Lewis式且同時識別芳香區域。
VMD程序里如果載入了xyz、gro、pdb等不含成鍵關系信息的文件(雖然pdb有CONECT字段,但VMD不利用),保存出的mol2文件將沒有BOND字段,明顯是不符合規范的。在同時載入拓撲文件以提供拓撲信息后,保存出的mol2文件才是有BOND字段的(與此同時也有了原子類型、原子電荷、原子所屬的殘基號和殘基名信息)。VMD如果載入的是mol2文件,也可以從中獲取成鍵信息,使得保存出的mol2文件里也有BOND部分。但是VMD并不能記錄芳香鍵,而且它自己也沒有像OpenBabel那樣根據幾何結構和元素就能判斷出芳香區域的能力,因此即便載入的是本例的benzaldehyde.mol2,保存出的mol2里苯環上的鍵也都會簡單地記錄成單鍵。
還值得順帶一提的是有個叫mol的格式,介紹見https://en.wikipedia.org/wiki/Chemical_table_file。不要將它和mol2混淆,二者格式截然不同。mol也能像mol2一樣記錄鍵的存在性及其類型。GaussView產生的mol文件中會把芳香鍵用4來記錄,這正是mol標準格式中的芳香鍵的類型序號,而OpenBabel在產生mol文件時則會把芳香環描述成單雙鍵交替的形式。
3 關于記錄晶胞信息
mol2文件通常用來記錄孤立體系,但實際上此格式也定義了記錄晶胞信息的字段@<TRIPOS>CRYSIN,在其下一行寫晶胞的a、b、c三個邊長(埃)以及alpha、beta、gamma夾角(度),每個值之間以逗號分隔。例如:
@<TRIPOS>CRYSIN
3.785,3.785,9.514,90,90,90
Sobtop和Multiwfn在載入mol2文件時都會試圖載入晶胞信息以考慮周期性。GaussView有很好用的對周期性體系建模的功能,但即便在圖形窗口里能看到晶胞邊框,代表當前是周期性體系,其保存出的mol2文件里也沒有@<TRIPOS>CRYSIN字段,因此需要自行補充。在VMD 1.9.3里,即便當前有晶胞信息,保存的mol2文件里也沒有以上字段。VMD 1.9.3載入mol2時也不會從以上字段中載入晶胞信息。
A lazy script for ORCA combined with Multiwfn to calculate RESP, RESP2 and 1.2*CM5 atomic charges
文/Sobereva@北京科音
First release: 2022-Mar-15 Last update: 2022-Aug-6
之前筆者在以下文章中提供了三個Linux shell腳本,分別用來自動調用機子里的Gaussian和Multiwfn程序實現一鍵計算1.2*CM5、RESP和RESP2原子電荷,它們對于做經典力場的分子動力學非常重要。
計算適用于OPLS-AA力場做模擬的1.2*CM5原子電荷的懶人腳本
http://www.shanxitv.org/585(http://bbs.keinsci.com/thread-21462-1-1.html)
計算RESP原子電荷的超級懶人腳本(一行命令就算出結果)
http://www.shanxitv.org/476(http://bbs.keinsci.com/thread-12858-1-1.html)
RESP2原子電荷的思想以及在Multiwfn中的計算
http://www.shanxitv.org/531(http://bbs.keinsci.com/thread-16190-1-1.html)
如今用免費的ORCA量子化學程序的人也很多,筆者寫了不少相關博文(http://www.shanxitv.org/category/ORCA/),在北京科音高級量子化學培訓班(http://www.keinsci.com/KAQC)里對ORCA的使用還有非常全面深入的講授。為了便于那些主要做分子動力學模擬、沒買Gaussian又不太懂ORCA程序使用的人也能便利地計算上述原子電荷,筆者寫了能自動調用ORCA和Multiwfn的計算那些電荷的Linux shell腳本。這些腳本提供在了Multiwfn程序文件包里(可以在Multiwfn主頁http://www.shanxitv.org/multiwfn免費下載),必須是2022年3月8日及以后更新的Multiwfn版本里才有,包括:
examples\RESP\RESP_ORCA.sh:計算RESP電荷的腳本
examples\RESP\RESP2_ORCA.sh:計算RESP2電荷的腳本
examples\scripts\1.2CM5_ORCA.sh:計算1.2*CM5電荷的腳本
這些腳本的用法和前述帖子里介紹的基于Gaussian的腳本精確一致,需要留意的地方也都相同,只不過腳本中調用Gaussian的地方變成了調用ORCA而已,故不再累述用法。如果不會裝ORCA的話看《量子化學程序ORCA的安裝方法》(http://www.shanxitv.org/451)。
這些腳本運行之前記得用文本編輯器打開,把ORCA=和orca_2mkl=后面的內容分別改為當前機子里實際的ORCA和orca_2mkl工具的路徑。并把nprocs=后面的值改為計算時要調用的CPU核心數。腳本里maxcore=后面的值是ORCA的每個并行進程的內存使用量(MB)上限,與nprocs的乘積必須明顯小于空余物理內存量,其默認值一般是合適的。如果空余物理內存不夠則需要適度減小maxcore或nprocs,而如果要算幾百個原子的大體系則需要適度加大maxcore,否則可能計算崩潰。
RESP_ORCA.sh和RESP2_ORCA.sh里默認用的優化級別和基于Gaussian的腳本(RESP.sh和RESP2.sh)有所不同,這里用的是ORCA才支持的B97-3c,因為這個級別做優化很快,結果準確度也不錯。由于這個差異,以及ORCA和Gaussian在溶劑模型的實現上有所差異,所以基于Gaussian和基于ORCA的腳本得到的RESP或RESP2電荷可能有零點零幾的差別,這點沒必要在意,都是合理的。
關于使用腳本時哪些溶劑可以直接用、溶劑名怎么寫,請在ORCA手冊里搜“solvents in the SMD library”查看內置的溶劑名列表。注意ORCA里有些溶劑名是帶空格的,對這種情況要把溶劑名用雙引號擴住,例如./RESP2_ORCA.sh HF.pdb 0 1 "ETHYL ETHANOATE"。
如果你的輸入的結構文件里的結構就已經足夠好,不想讓腳本自動再做優化浪費時間,可以用examples\RESP\目錄下的RESP_ORCA_noopt.sh和RESP2_ORCA_noopt.sh分別代替前述的RESP_ORCA.sh和RESP2_ORCA.sh,它們的用法完全一樣,只不過帶_noopt后綴的不做優化步驟。
使用這些腳本計算原子電荷發表文章的話必須在文中恰當引用Multiwfn,引用方式在《Multiwfn FAQ》(http://www.shanxitv.org/452)里明確說了。并且注意在網上提問、描述情況的時候要明確說是使用本文提供的腳本,用Multiwfn基于ORCA產生的波函數計算RESP或RESP2電荷(我在網上答疑時老看到有人說成是“ORCA計算了RESP電荷”,明顯是大錯特錯,ORCA自己根本沒有算RESP電荷的功能)。
]]>Using Sobtop to create GROMACS topology file for ferrocene super conveniently
文/Sobereva@北京科音 2022-Feb-17
0 前言
Sobtop是筆者開發的主要用于產生各種類型體系的GROMACS拓撲文件的程序,可以在主頁http://www.shanxitv.org/soft/Sobtop免費下載。過渡金屬配合物體系的拓撲文件在以往是很難產生的一類情況,因為里面牽扯到GAFF、OPLS-AA、GROMOS等主流有機分子力場不支持的元素,里面涉及到的鍵/鍵角/二面角參數在那些力場里也沒有,所以acpype、Ligpargen、ATB等程序根本沒法搞。而這類體系,用Sobtop則可以超級容易地產生拓撲文件。AmberTools里的MCPB.py程序雖然能產生這類體系的拓撲文件,但是過程麻煩至極,在http://bbs.keinsci.com/thread-27796-1-1.html里有人演示了怎么借助MCPB.py產生二茂鐵的GROMACS的拓撲文件,估計大多數人看了后會打退堂鼓。Sobtop的詳情以后會另文專門系統性地介紹,本文僅簡單演示一下怎么用Sobtop快捷地產生二茂鐵的拓撲文件,通過對比大家可以充分認識到用Sobtop有多么方便。
本文牽扯到的所有輸入輸出文件都可以在http://www.shanxitv.org/attach/635/file.rar里找到。Sobtop用的是2022-Feb-16發布的預覽版1.0(dev)。Multiwfn用的是2022-Feb-17更新的版本,Multiwfn可以在主頁http://www.shanxitv.org/multiwfn免費下載。
1 用Gaussian做優化和振動分析
首先用Gaussian對二茂鐵做優化和振動分析。要注意,二茂鐵的兩個茂環間僅在低溫晶體中是交錯式的,而在真空中極小點結構是重疊式的(參看Materials, 8, 7723 (2015)和https://en.wikipedia.org/wiki/Ferrocene#Determining_the_structure中的相關信息),因此本例用重疊式(D5h點群)的初始結構。記得Gaussian計算前最好用GaussView做對稱化,這樣優化得又精準速度又快。
關于計算級別,本例用的TPSSh/def2-TZVP級別對于過渡金屬配合物體系通常是很理想的選擇。關于泛函的選擇看《簡談量子化學計算中DFT泛函的選擇》(http://www.shanxitv.org/272)。如果想明顯更便宜,Fe可以用SDD,配體可以用6-311G*。
此例的Gaussian輸入文件如下
%chk=Ferrocene.chk
#p tpssh/def2tzvp opt freq
[空行]
Generated by Multiwfn
[空行]
0 1
C 0.71056100 -0.97800331 1.65426528
C -0.00000000 1.20887857 1.65426528
C -0.71056100 -0.97800331 1.65426528
H 2.17848562 0.70783289 1.62195576
H -2.17848562 0.70783289 1.62195576
Fe 0.00000000 0.00000000 -0.00000000
C 1.14971184 0.37356402 1.65426528
C -1.14971184 0.37356402 1.65426528
H 1.34637816 -1.85313055 1.62195576
H -0.00000000 2.29059533 1.62195576
H -1.34637816 -1.85313055 1.62195576
C 1.14971184 0.37356402 -1.65426528
C -1.14971184 0.37356402 -1.65426528
C 0.71056100 -0.97800331 -1.65426528
C 0.00000000 1.20887857 -1.65426528
C -0.71056100 -0.97800331 -1.65426528
H 2.17848562 0.70783289 -1.62195576
H -2.17848562 0.70783289 -1.62195576
H 1.34637816 -1.85313055 -1.62195576
H 0.00000000 2.29059533 -1.62195576
H -1.34637816 -1.85313055 -1.62195576
[空行]
[空行]
算完了之后,用formchk把當前目錄下的Ferrocene.chk轉換為Ferrocene.fchk。不知道formchk是什么和怎么用的話看《詳談Multiwfn支持的輸入文件類型、產生方法以及相互轉換》(http://www.shanxitv.org/379)里相關部分。
還需要得到二茂鐵的mol2文件,并且要求其中記錄的鍵連關系和期望的一致,這決定了Sobtop給出的拓撲文件里都有哪些力場項。很多程序都可以實現這個,此例我們用常用的GaussView打開Ferrocene.fchk,如果看到Fe和各個C之間沒顯示鍵的話就手動連上(設幾重鍵都無所謂,Sobtop只看有沒有鍵)。然后保存為Ferrocene.mol2。
2 計算RESP電荷
RESP電荷很適合用于動力學模擬的目的,我們要讓拓撲文件里的原子電荷對應RESP電荷。計算RESP電荷非常強大、方便、靈活的程序是Multiwfn,見《RESP擬合靜電勢電荷的原理以及在Multiwfn中的計算》(http://www.shanxitv.org/441)。要注意對二茂鐵體系不宜直接按照常規方式算RESP電荷,因為擬合點的分布不會恰好滿足D5h對稱性,因此得到的等價原子的原子電荷會有微小的偏差。為了讓所有等價的原子的電荷都嚴格相同,在Multiwfn中計算RESP電荷時應當設置等價性。
啟動Multiwfn,然后輸入
Ferrocene.fchk
7 //計算原子電荷
18 //計算RESP電荷
5 //等價性約束設置
11 //根據點群自動判斷等價性
a //根據整個體系的結構判斷點群
y //當前屏幕上顯示的點群確實是D5h,列出的原子等價性沒錯,所以這里輸入y確認。然后當前目錄下有了等價性設置文件eqvcons_PG.txt
q //返回
1 //從文本文件里讀取等價性設置
eqvcons_PG.txt //剛才產生的文件
2 //開始一步式RESP電荷擬合
[回車] //程序提示Fe缺半徑,按回車表示用推薦的半徑
Multiwfn算RESP電荷效率很高,RESP電荷很快就產生了,從屏幕上給出的結果看確實原子電荷合理,而且滿足等價性。按y把產生的原子電荷導出為當前目錄下的Ferrocene.chg。
3 用Sobtop產生拓撲文件
啟動Sobtop,然后依次輸入
Ferrocene.mol2
7 //指定原子電荷
10 //從Multiwfn的chg文件中讀取原子電荷
Ferrocene.chg
0 //返回
2 //產生GROMACS的.gro文件
[回車] //此時當前目錄下產生了Ferrocene.gro
1 //產生GROMACS的拓撲文件
2 //優先用GAFF原子類型,缺的自動用UFF力場的。原子類型決定了拓撲文件里的LJ參數
2 //所有成鍵相關參數基于振動分析產生的fchk文件里的Hessian矩陣生成
Ferrocene.fchk //如果此文件和Ferrocene.mol2在相同目錄下,此處直接按回車可以快捷載入
[回車] //在當前目錄下產生Ferrocene.top
[回車] //在當前目錄下產生Ferrocene.itp
現在拓撲文件在當前目錄下出現了,Sobtop可以關了。現在可以打開itp文件看看內容,會看到沒有任何問題,文件整齊干凈,注釋也特別清楚。
4 測試拓撲文件合理性
產生拓撲文件之后,我一般建議在真空下對這個體系跑一下動力學,根據模擬過程中結構變化情況大致判斷拓撲文件是否合理。做這個模擬要用的Ferrocene.gro、Ferrocene.top、Ferrocene.itp前面我們都已經產生了。做這個模擬用的md.mdp在本文的文件包里也給了,可見是控溫在298.15K下模擬100 ps,1 fs一步,每100 fs往xtc里寫入一幀,沒有用PBC。筆者此例用的是GROMACS 2018.8。這個mdp不兼容GROMACS較新版本,較新版本用戶需要在一個足夠大的空盒子里在考慮PBC的情況下跑NVT模擬。
把前述的gro、itp、top、mdp都放到當前目錄下,運行以下命令
gmx grompp -f md.mdp -c Ferrocene.gro -p Ferrocene.top -o md.tpr
gmx mdrun -v -deffnm md
然后用VMD載入軌跡,用Extensions - Analysis - RMSD Trajectory Tool工具對system選區做align消除平動轉動后,每10幀疊加顯示一次,得到下圖
可見模擬過程中二茂鐵很好地維持了剛性,說明拓撲文件合理。
5 總結&其它
本例充分體現了使用Sobtop結合Multiwfn程序產生過渡金屬配合物體系拓撲文件的便利,把復雜度降低到了極限。此文只以極為簡單的體系做了示例,對更復雜的情況,諸如多核金屬配合物、除了剛性部分還帶有可旋轉鍵的柔性部分的配合物,Sobtop也都能很容易地產生拓撲文件。凡是體系全為剛性的情況都可以直接效仿本文的做法;對于既有剛性配位區域也有柔性基團的配合物,在Sobtop問你怎么產生成成鍵相關(bonded)參數時,建議選擇相應選項,讓bond和angle參數用特定方法基于Hessian產生,而其它的用預置力場參數,這樣可以使得GAFF的參數用于描述柔性部分二面角可旋轉特征。
實際中二茂鐵的茂環的旋轉勢壘是非常低的,常溫下是可以旋轉的,但本文得到拓撲文件對應的是純剛性二茂鐵。本文暫不考慮茂環間可相對旋轉的問題,這也不是什么重要問題。
本文的做法比起MCPB.py實在方便百倍,而且MCPB.py用的Seminario方法產生力常數也不如本文的方法合理(當前版本Sobtop默認用的是modified Seminario,產生的鍵角力常數遠好于Seminario)。
做優化和振動分析用免費的ORCA亦可,文中用fchk的地方改成用ORCA振動分析產生的.hess文件即可。
對于體系沒有對稱性的情況,算RESP電荷時不需要本文這樣做對稱等價設置,直接在Multiwfn的RESP界面里選擇1用常規的兩步式擬合即可。更多細節看《RESP擬合靜電勢電荷的原理以及在Multiwfn中的計算》(http://www.shanxitv.org/441)。
本文的例子直接從chg文件中載入了RESP電荷。也可以在Sobtop里先不設置電荷,等itp產生出來之后再手動把要用的電荷寫入到[ atoms ]部分。
使用Sobtop產生拓撲文件發表文章時記得按照Sobtop主頁http://www.shanxitv.org/soft/Sobtop的說明進行引用。引用方式在未來會有所變化,請記得發文章之前看一下主頁上最新的引用說明。
]]>