硬盤速度與內存容量對量子化學計算速度影響的測試
1 前言
本文的目的是通過幾種主流量子化學程序的實測數據,說明量子化學計算用的機子有沒有必要用大內存,有沒有必要用高速硬盤,這倆問題是購買服務器的人很關注的問題。經常有人認為內存容量只要讓計算得以進行就夠了,加大內存對提升速度并沒用處,本文也通過測試看看是否是這么回事。本文測試用的機子是雙路XEON E5-2696v3(2*18=36個物理核心),主板X10DRL-i。機子內存比較大,是8*32GB DDR4-2133,共256GB,因此有較大余地測試內存對計算速度的影響。購機過程在這里有詳細記錄《淘寶店購買雙路2696v3服務器的過程、使用感受和雜談》(http://bbs.keinsci.com/forum.php?mod=viewthread&tid=6310)。在買這臺機子數日之后,又買了個三星PM961,花了1289軟妹幣。此時機子里一共有三個硬盤:
(1)希捷4T企業版
(2)影馳鐵甲戰將SATA3 480GB固態硬盤
(3)三星PM961,是M.2口512GB高速固態硬盤
這三個硬盤,連續讀寫速度依次由慢到塊,正好可以用來對比硬盤速度對量化計算的影響。三塊硬盤性能測試如下(Win10-64bit):
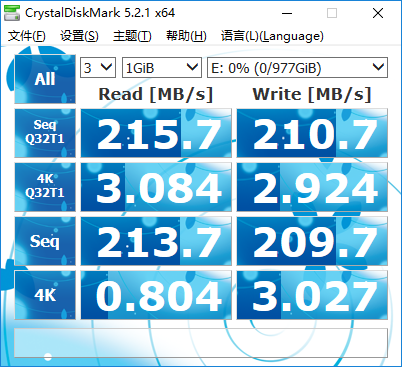
希捷4T企業版
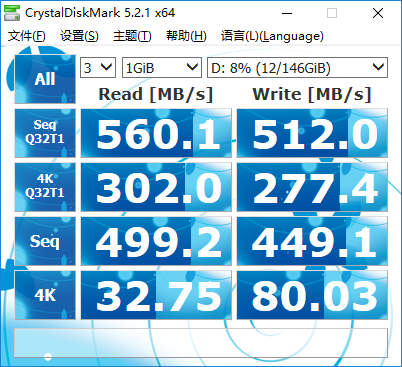
影馳鐵甲戰將
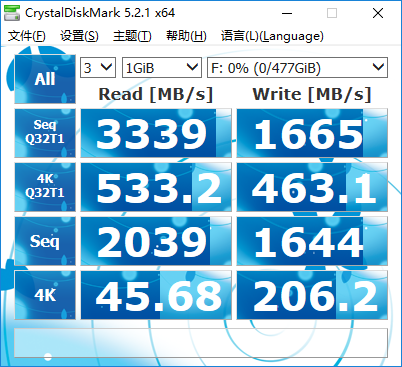
PM961
2 關于硬盤速度和PM961
之所以筆者機子之前已經有一個大容量機械和一個固態了,而后來又買了PM961,是因為PM961的性能遠遠超過SATA3口的固態硬盤。SATA3對SSD的限制已經愈發明顯,早已不是可忽視的程度了。如影馳鐵甲戰將測試成績所示,SATA3的SSD一般持續讀寫速度也就做到五六百MB/s,而走M.2或PCI-E 3.0 4x口的SSD,如PM961,則完全脫離了這個束縛,連續讀寫性能完爆SATA3硬盤。還在慣用SATA3 SSD的人應該轉變觀念了。在M.2/PCI-E的SSD普及之前,一些人為了追求更好性能,把SATA3 SSD組Raid0,性能確實提高很多,但是相對于如今的M.2/PCI-E的SSD,已經是雞肋了。量化計算有的任務基本不怎么讀寫硬盤,比如DFT單點、優化,對這類任務顯然用什么硬盤都不會影響性能;而有的任務則會產生巨大的臨時文件并大量讀寫,諸如CCSD(T),因此硬盤速度必然會對性能產生不可忽視的影響。本文說的硬盤速度一律是指硬盤的連續讀寫速度,而不是隨機讀寫速度,后者只影響大量操作小文件的速度(在計算化學范疇中,對于化學信息學、虛擬篩選等問題才可能產生較明顯影響)。
筆者購買PM961的目的不是用來為了裝系統、讓應用程序啟動速度更快,而純粹是把這塊硬盤當苦力用。各種量化程序的臨時文件都在這里讀寫,而不裝任何程序和資料,因此就算這硬盤因為累計讀寫量太大壞掉,也不會造成其它損失,找店家換貨就完了。對于經常要跑后HF任務的人,手頭不太緊的話,建議苦力盤容量不要買256GB的,建議>=512GB,因為對于大體系后HF任務,臨時文件達到三四百GB甚至更多都是不少見的(對于Gaussian,由于可以方便地對rwf文件進行分割,因此還好。而大多數程序臨時文件只能指定在一個目錄下讀寫,苦力盤容量不夠就比較麻煩了)。
由于大多數讀者對三星PM961比較陌生,這里多說幾句。PM961類似于三星高端固態硬盤960EVO的OEM貨,無包裝,性能沒什么差別,價格便宜很多,淘寶店一般都提供質保,筆者買的這個店家3年包換:

筆者服務器的X10DRL-i主板并沒有M.2口,沒法直接用PM961,因此在淘寶上花20塊錢買了個佳翼SK4轉接卡,用來將M.2轉換為PCI-E 3.0 4x口

為了散熱好點,又花18塊錢買了個散熱條,組裝好后:

剛上手把玩一會兒后截的硬盤信息
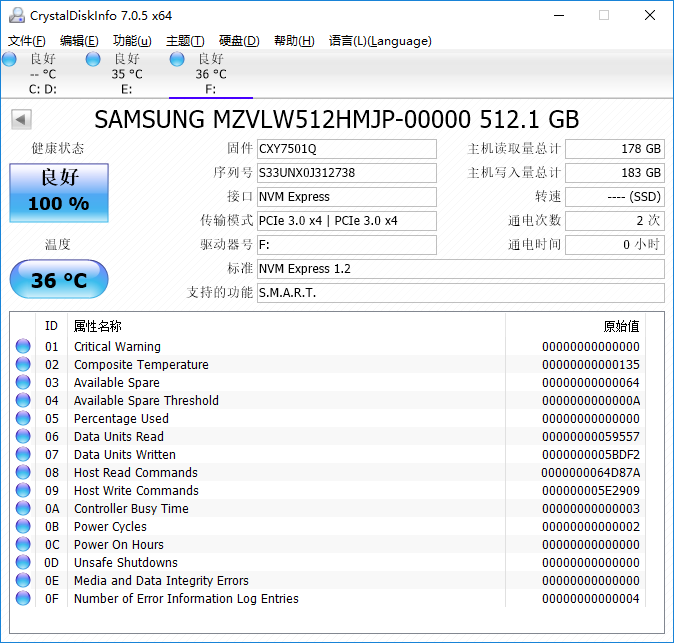
估計會有人懷疑,這么轉接一下,性能肯定打折扣吧?會不會不穩定?從上面的速度實測已經充分說明,用這個轉接卡速度絲毫不打折扣,完全不影響PM961頂級性能的發揮。而且根據3個月的使用感受,也未曾發現有不穩定的情況。所以以上轉接方式非常穩妥。
雖然買原本就是PCI-E口的固態硬盤就能免得轉接一下,但筆者強烈不建議購買,因為性價比遠遠低于PM961。例如PCI-E 3.0 4x的浦科特M8SeY 512GB,性能不及PM961,卻還要賣到2000出頭。市面上也有其它M.2口的SSD,同等容量價格和PM961差不多,比如Intel 600P 512GB,但性能都落后于PM961,所以也不建議購買。
順帶一提PM961在這里可以下載三星官方驅動http://www.samsung.com/semiconductor/minisite/ssd/download/tools.html,對于Win10,裝不裝對測試性能影響不大。
3 關于將內存虛擬成硬盤
硬盤既可以虛擬成內存,內存也可以虛擬成硬盤。當內存非常大,又無用武之地時,把內存虛擬成硬盤,從而加速大量讀寫硬盤任務的速度往往是有用的做法。雖說PM961已經很快了,但是跟服務器的內存讀寫性能來比還有一個以上數量級的差距。Linux下可以用ramfs或者tmpfs方式把內存虛擬成硬盤,兩種做法實測性能沒什么差異,筆者比較習慣用ramfs的做法。使用非常簡單,比如要把最多180GB內存作為虛擬硬盤掛載到/vram目錄,就執行以下命令mkdir /vram
mount none /vram -t ramfs -o maxsize=180G
這樣在/vram里讀寫文件就相當于在內存中讀寫了。無論是運行umount /vram手動卸載之,還是重啟,/vram里面的文件都會消失。
后文將測試,對于后HF任務,把大內存充分分配給程序耗時更低,還是只把部分內存分配給程序,而把另一部分內存作為虛擬硬盤用于讀寫臨時文件耗時更低。
4 內存容量與硬盤速度對計算耗時的影響實測
下面將通過最常用的量化程序Gaussian16 A.03和ORCA 4.0.1.2(皆64bit),執行不同類型任務,來考察分配的內存量和硬盤速度對計算耗時的影響,看看買服務器時錢怎么花最劃算。測試機子的硬件配置上面已經說過了,系統是CentOS 7.3 64bit。所有測試的項目都是對內存容量、硬盤有一定要求的,而普通泛函算單點、優化這類問題,占內存很少,也不怎么讀寫硬盤,因此不納入測試。下面測試的耗時一律都是指wall clock time,不是CPU time。每次測試的計算耗時都有可能略有不同,因此如果兩個計算條件耗時相差不多的話,就當成沒有差異即可。測試中涉及到的體系如下,選的體系比較貼近于現階段大家通常計算的大小,并沒有刻意去選巨大體系(對于巨大體系,測試結論可能會有所不同,但這不是本文關注的):
4.1 Gaussian16
以下Gaussian計算若未注明,則默認計算設置為%nproc=36 %mem=245GB,且rwf文件產生大小不設上限。測試中除了Ru(bpy)3外都沒有利用對稱性以加速。(1)振動分析。BNtube。關鍵詞B3LYP/6-31G* freq nosymm。實際產生rwf文件1.5GB。
PM961:24m11s
影馳鐵甲戰將:24m27s
希捷4TB:24m29s
%mem=60GB + PM961:24m15s
可見,由于普通泛函下振動分析任務的臨時文件小,硬盤速度對耗時基本沒有影響,內存分配大小也不影響耗時。
(2)超極化率計算。DA3。關鍵詞CAM-B3LYP/6-311++G(2df,p) polar nosymm。實際產生rwf文件314MB。
PM961:20m28s
影馳鐵甲戰將:20m32s
希捷4TB:20m35s
%mem=60GB + PM961:20m35s
情況如振動分析,內存容量和硬盤速度對耗時基本也沒有影響。
(3)TDDFT。Ru(bpy)3。關鍵詞B3LYP/genecp TD(nstates=30)。對Ru用的SDD,其它原子6-311G*。實際產生rwf文件7.6GB。
PM961:15m37s
影馳鐵甲戰將:15m32s
希捷4TB:15m31s
%mem=60GB + PM961:15m36s
這個測試還是沒發現硬盤速度和內存分配量對總耗時有什么影響。
(4)MP2單點。DA3。關鍵詞MP2/def2TZVP nosymm。實際產生rwf文件150GB。
PM961:13m28s (此數據比較異常,原因不明,不做討論)
影馳鐵甲戰將:12m44s
希捷4TB:13m20s
%mem=60GB + PM961:12m42s
%mem=60GB + 180GB vram:12m22 (vram指把內存虛擬成硬盤)
這個任務由于rwf文件比較大,終于一定程度體現出硬盤速度對耗時的影響。影馳SSD比機械硬盤快了一些。如果用vram,速度還能再快一點。不過此任務依然沒有很充分體現出大內存或高速硬盤的效果。
值得注意的是,如果把rwf文件產生的上限人為設為100GB,程序發現可用空余硬盤空間不夠,會自動用FullDirect方式做MP2,此時rwf大小僅有268MB,而作為代價,計算耗時較高,為16m17s。
(5)CCSD(T)單點。苯胺。關鍵詞CCSD(T)/cc-pVTZ。實際產生rwf文件在CCSD迭代時為21GB,計算(T)時為79.4GB(且占內存達到>90%)。
PM961:26m18s
影馳鐵甲戰將:34m32s
希捷4TB:62m52s
%mem=60GB + PM961:20m21s
%mem=60GB + 180GB vRAM:19m18s
在CCSD(T)計算時,終于體現出了硬盤速度對計算耗時的巨大影響!SATA3的SSD比機械硬盤快了近一倍,如果用更快的SSD,即PM961,耗時還可以進一步下降。測試中還看到一個違背一般直覺的事,就是分配的內存從245GB降到60GB,耗時反倒從26m18s降到了20m21s,看似內存分配大了還有害。應該說這是G16程序的缺陷所致,實際上在G09,以及其它體系的CCSD(T)計算上也都發現了這個情況。既然內存給大了反倒耗時增高,而且CCSD(T)對硬盤性能敏感,那么少給點內存,而把富裕的內存虛擬成硬盤,豈不美哉?事實也證明此做法奏效,如上述數據所示,把180GB內存虛擬成硬盤來讀寫rwf的話,耗時比用PM961進一步降低,不過降低得不算很大了,因為PM961已經很快了,此時硬盤讀寫速度的瓶頸已經沒那么顯著了。
還有兩種特殊情況:
PM961(rwf上限設15GB):會報錯Transformation cannot fit in the specified MaxDisk.
PM961(rwf上限設25GB):31m32s(到了(T)那一步,由于硬盤不夠,提示Number of processors reduced to 6 in MP4TCl:,之后CPU只有600%占用了)
這體現出CCSD(T)對硬盤空余容量是有較高要求的。剩余容量達不到最低要求,根本算不了;剩余容量太小,則并行度會自動降低,明顯降低計算速度。
(6)SCF=conventional單點。DA3。關鍵詞HF/def2TZVP nosymm。實際產生rwf文件為192GB。
PM961:23m30s
希捷4TB:29m27s
這個測試其實沒什么意義,只不過由于SCF=conventional把電子積分全寫到rwf里,硬盤讀寫量會很大,所以隨便測試了一下硬盤速度的影響。可見PM961比機械硬盤還是有明顯優勢的,只不過沒有預期的那么夸張。SCF=conventional現在根本沒人用,因為以direct方式做SCF,此任務僅需要2m59s,rwf文件僅有269MB。即曰,哪怕有高速硬盤,conventional還是遠不如direct。還嘗試了用incore方式做SCF,此時占內存高達223GB,rwf文件為182MB。雖然incore時積分都存在內存里,理應比direct快,但是實際耗時高達11m12s,是因為Gaussian的incore模式做得不好,CPU利用率非常低,而且用direct時還可以用積分屏蔽等技巧來加速。
4.2 ORCA 4.0.1.2
ORCA是MPI方式并行,maxcore設的是每個MPI進程最多用的內存量(MB)。由于實際使用量可能超過maxcore,因此必須留有一定富余。計算時候皆為36核并行,對于256GB機子來說,maxcore=6000比較穩妥,而64GB機子來說,maxcore=1400一般沒問題。(1)雙雜化單點。BNtube。關鍵詞RI-PWPB95 def2-QZVPP def2/JK def2-QZVPP/C RIJK。臨時文件占硬盤最多用到15GB
maxcore=6000,影馳鐵甲戰將:20m16s
maxcore=6000,PM961:20m20s
maxcore=6000,希捷4TB:20m18s
maxcore=1400,PM961:24m50s
即便此體系不小了,計算級別還挺高,但對于此任務,硬盤讀寫仍不構成瓶頸,沒體現出硬盤速度對耗時的影響。而內存分配量對耗時有一定影響,給大了耗時會降低。
(2)DLPNO-CCSD(T)單點。DA3。關鍵詞DLPNO-CCSD(T) def2-TZVP def2/JK def2-TZVP/C RIJK tightSCF。臨時文件占硬盤最多用到15GB
maxcore=6000,影馳鐵甲戰將:18m37s -817.155278103676
maxcore=6000,PM961,帶tightPNO:78m21s -817.160700708131(臨時文件占硬盤最多用到44GB)
maxcore=6000,PM961:18m39s
maxcore=6000,希捷4TB:18m44s
maxcore=1400,PM961:18m47s
DLPNO-CCSD(T)是ORCA獨家的降低CCSD(T)耗時的重要方法,這體系直接用CCSD(T)在現有條件下是絕對算不動的,而做DLPNO-CCSD(T)則輕而易舉。從測試來看,硬盤速度和內存分配量并未對DLPNO-CCSD(T)耗時有明顯影響。還順帶測試了帶著tightPNO關鍵詞的情況,這使得DLPNO-CCSD(T)比默認設定下更逼近CCSD(T)的結果,不僅耗時增加幾倍,對硬盤空余空間的要求也顯著增加了。
(3)CCSD(T)單點。苯胺。關鍵詞CCSD(T) cc-pVTZ tightSCF。臨時文件占硬盤最多用到29GB
maxcore=6000,PM961:13m9s
maxcore=6000,希捷4TB:13m6s
maxcore=1400,PM961:16m17s
和Gaussian不同的是,ORCA里做CCSD(T),高速硬盤并沒發揮什么用處,而分配大內存,和雙雜化計算時一樣會使得耗時降低。
4.3 Molpro 2015
對Molpro 2015只是做個簡單測試,CCSD(T)/cc-pVTZ單點。苯胺。Molpro也是MPI并行的程序,-m后面設的是每個進程的內存使用量上限,800m代表800mwords*8=6.4GB。-n后面是并行核數。在測試時發現Molpro的計算耗時的重現性比較差,所以僅供粗略參考-m 800m -n 36,PM961:10m20s
-m 400m -n 36,PM961:10m55s
-m 100m -n 36,PM961:10m51s
-m 800m -n 36,影馳鐵甲戰將:11m10s
-m 800m -n 36,希捷4TB:12m9s
-m 100m -n 36,希捷4TB:12m31s
-m 100m -n 36,180GB vRAM:10m37s
-m 800m -n 18,PM961:11m55s
-m 800m -n 8,PM961:21m52s
-m 3500m -n 8,PM961:19m5s
對比測試數據,可以看到硬盤相同時,加大內存可以令耗時有一定降低;內存相同時,硬盤速度越快耗時也會越低。只不過兩個因素對速度影響有限,最快的“-m 800m -n 36,PM961”也就比最慢的“-m 100m -n 36,希捷4TB”快了1/5。
PS:可對比以上列出的Gaussian、ORCA、Molpro在同樣級別計算苯胺的速度,了解這三個程序做耦合簇的速度差異。5 總結
從以上測試看出,內存分配量、硬盤速度,都可能對計算速度產生影響,對不同程序的影響情況還不一樣。對一般體系,這兩個因素能起到不可忽略的影響主要是對后HF類型任務(也包括雙雜化),如果不主要計算這類任務,不必買太大內存(至多128GB足夠),也不是必須上高速硬盤。對于用Gaussian做耦合簇的人,買個PM961這樣的高速硬盤是很值得的,以很少的代價就可以讓速度提升很多。但是沒必要刻意花錢買大內存,內存分配過大了反倒可能有害;如果機子里已經有比較大內存,那么不妨把富裕的內存當虛擬硬盤用,能令耦合簇耗時降低不少(就算虛擬的硬盤容量不足以塞入整個rwf也沒關系,可以用%rwf設定分割rwf)。
對于ORCA用戶,用高速硬盤沒太大必要,起碼本文測試沒體現出高速硬盤帶來的好處。買大內存以提升性能是可以的,但是不要指望內存設大了,耗時就能降低達到一倍的程度。值不值得花那份錢,應自行斟酌。
總的來說,鑒于硬盤比較便宜,對于量化計算用戶,個人建議花一千出頭買一個512GB PM961當苦力用。而在有限的預算下,買大內存和提升CPU檔次之間,建議先考慮后者,更劃算。
還值得一提的是,本文的測試結論與CPU性能必定是存在一定關聯的,因為這會影響性能瓶頸的構成。