通過設置CPU內核綁定降低ORCA同時做多任務的耗時
通過設置CPU內核綁定降低ORCA同時做多任務的耗時
文/Sobereva@北京科音 2020-Jun-1
1 前言
由于任何程序的并行效率都是隨著核數增加而降低,當機子核數比較多的時候,比如有好幾十核,而且又有許多任務要跑的時候,比起一個一個調用所有核心來跑,同時跑兩個或者多個任務但是每個都用較少的核心數(總和不超過物理核心數),總耗時通常會更低。對于某些程序跑某些任務,甚至并行核數較少的時候反倒比核數較多的時候速度還更快。因此在核數較多的機子上,同時跑多個任務是很常見的事情。
然而,同時跑多個任務涉及到資源爭搶問題,如果爭搶得比較厲害,跑多個任務的效率會大打折扣,甚至可能還不如一個一個用所有核來跑。
如今很多程序在并行計算的時候都支持線程或進程與CPU內核的綁定,從而避免操作系統自動調度導致任務在不同CPU核心上頻繁切換執行引起運行效率的下降,恰當綁定也可以有效降低CPU資源爭搶問題。ORCA自身沒有直接提供內核綁定的設置,但可以通過自行指定OpenMPI的運行選項來實現,本文就說說具體做法和實際效果。
2 CPU內核綁定的實現
2.1 在ORCA運行時使用內核綁定
ORCA在Linux下并行一般結合OpenMPI使用,本文也只說OpenMPI的情況。OpenMPI基于hwloc庫來獲取硬件信息,而hwloc庫又要利用libnuma。只有在編譯OpenMPI時提供了libnuma靜態庫,之后ORCA運行時才能借助OpenMPI的設置實現內核綁定。多數情況下系統里是沒有裝libnuma靜態庫的,對于CentOS 7.x,可以通過yum install numactl-devel命令來裝上,之后再按照《量子化學程序ORCA的安裝方法》(http://www.shanxitv.org/451)里說的照常編譯OpenMPI就可以了。
ORCA運行命令中可以加入傳遞給OpenMPI的mpirun的選項,比如:
orca test.inp "--bind-to core"
此時ORCA利用mpirun來運行其支持并行的模塊的時候就會把--bind-to core選項傳遞給mpirun。OpenMPI 3.1.x版的mpirun支持的選項在這里都能看到:https://www.open-mpi.org/doc/v3.1/man1/mpirun.1.php,其中就包括了內核綁定的設置的說明。
2.2 內核綁定規則的設置
mpirun的選項中--bind-to [值]指定的是綁定的對象什么,而--map-by [值]是設定按照什么順序循環被綁定物。例如當前機子是雙路的,每個CPU有六個核,看以下兩種情況:
--bind-to core --map-by core:按照循環各個核的順序綁定,圖例如下。B是代表運行當前進程的CPU核心
進程0:[B . . . . .][. . . . . .]
進程1:[. B . . . .][. . . . . .]
進程2:[. . B . . .][. . . . . .]
進程3:[. . . B . .][. . . . . .]
...略
這表明進程0綁定了第一個CPU的第一個核心,只有這個核心被用來跑這個進程。
--bind-to socket --map-by socket:按照循環各個CPU的順序綁定(socket此處是指CPU插槽),圖例如下
進程0:[B B B B B B][. . . . . .]
進程1:[. . . . . .][B B B B B B]
進程2:[B B B B B B][. . . . . .]
進程3:[. . . . . .][B B B B B B]
...略
可見,此時進程0綁定了第一個CPU的所有核心,這些核心一起執行這個進程,而第二個CPU核心不會跑這個進程。
mpirun加上--report-bindings選項可以在開始并行執行時顯示當前是怎么綁定的,用以確認綁定方式合乎自己的要求。
如果想精細控制綁定規則,需要創建rankfile文件。比如rankfile文件是/sob/miku.txt,可以這么運行./violet.x程序:mpiexec -np 3 -rf /sob/miku --report-bindings ./violet.x,此時一共3個進程會按照rankfile里指定的方式來綁定。
比如rankfile文件內容如下
rank 0=Saber110 slot=1:0,1
rank 1=Saber109 slot=0:*
rank 2=Saber108 slot=1:1-3
rank 3=Saber17 slot=0:1,1:0-2
rank 4=Saber109 slot=0:*,1:*
rank 5=Saber109 slot=0-2
就意味著(注意此處進程、CPU編號和核心編號都是從0開始的)
第0個進程與Saber110節點的第1號CPU的0、1兩個核心綁定
第1個進程與Saber109節點的第0號CPU的所有核心綁定
第2個進程與Saber108節點的第1號CPU的1、2、3核心綁定
第3個進程與Saber17節點的第0號CPU的1號核心,以及第1號CPU的0~2號核心綁定
第4個進程與Saber109節點的第0、1號CPU的所有核心綁定
第5個進程與Saber109節點的第0、1、2號邏輯核心綁定
如果比如當前是-np 3跑3個進程,則只有前3個規則生效,而rank 3、rank 4、rank 5的設置不會被利用。
2.3 讓每個ORCA任務獨占不同的CPU核心
如果只跑一個任務的話,設內核綁定沒什么用處。而跑多個任務時,給不同任務指定不同的CPU核心可用范圍,則有可能降低CPU資源爭搶來降低耗時。為此,需要設置不同rankfile。比如雙路共36核72線程機子,其邏輯核心的序號是下面的順序:
第一個CPU的18個物理核心:依次為0~17
第二個CPU的18個物理核心:依次為18~35
第一個CPU的18個虛擬核心:依次為36~53
第二個CPU的18個虛擬核心:依次為54~71
更確切來說,比如0和36號邏輯核心的任務其實都是第一個CPU的實際的0號核心做的,如果就是一個MPI進程要跑,在0還是36號上執行速度都一樣,但如果有兩個MPI進程,若在0和36號上面同時跑,速度就只有之前的約一半了。詳見《正確認識超線程(HT)技術對計算化學運算的影響》(http://www.shanxitv.org/392)。下文就忽略掉由于超線程技術而多出來的36~71號核心了。
如果有兩個ORCA任務要跑,每個都設nprocs 18,那么默認的情況下,每個任務會同時在兩個CPU上跑,有可能存在資源爭搶。如果希望這兩個任務分別在第一和第二個CPU上跑,可以設置這以下兩個rankfile文件。
CPU1.txt,內容為
rank 0=2696v3 slot=0:0
rank 1=2696v3 slot=0:1
rank 2=2696v3 slot=0:2
rank 3=2696v3 slot=0:3
rank 4=2696v3 slot=0:4
rank 5=2696v3 slot=0:5
rank 6=2696v3 slot=0:6
rank 7=2696v3 slot=0:7
rank 8=2696v3 slot=0:8
rank 9=2696v3 slot=0:9
rank 10=2696v3 slot=0:10
rank 11=2696v3 slot=0:11
rank 12=2696v3 slot=0:12
rank 13=2696v3 slot=0:13
rank 14=2696v3 slot=0:14
rank 15=2696v3 slot=0:15
rank 16=2696v3 slot=0:16
rank 17=2696v3 slot=0:17
CPU2.txt,內容為
rank 0=2696v3 slot=1:0
rank 1=2696v3 slot=1:1
rank 2=2696v3 slot=1:2
rank 3=2696v3 slot=1:3
rank 4=2696v3 slot=1:4
rank 5=2696v3 slot=1:5
rank 6=2696v3 slot=1:6
rank 7=2696v3 slot=1:7
rank 8=2696v3 slot=1:8
rank 9=2696v3 slot=1:9
rank 10=2696v3 slot=1:10
rank 11=2696v3 slot=1:11
rank 12=2696v3 slot=1:12
rank 13=2696v3 slot=1:13
rank 14=2696v3 slot=1:14
rank 15=2696v3 slot=1:15
rank 16=2696v3 slot=1:16
rank 17=2696v3 slot=1:17
這里2696v3是當前的主機名,運行hostname命令時顯示什么就填什么(如果顯示的是IP號,這里就填IP號)。
假設這兩個rankfile文件都在/sob目錄下,然后執行以下兩條命令分別跑ORCA任務
orca MD1.inp "-rf /sob/CPU1.txt" > MD1.out
orca MD2.inp "-rf /sob/CPU2.txt" > MD2.out
則MD1和MD2任務就分別只在第一個和第二個CPU上跑了
如果你有四個任務要跑,每個任務給9個核,那么可以創建四個rankfile:
CPU1a.txt的內容
rank 0=2696v3 slot=0:0
rank 1=2696v3 slot=0:1
rank 2=2696v3 slot=0:2
rank 3=2696v3 slot=0:3
rank 4=2696v3 slot=0:4
rank 5=2696v3 slot=0:5
rank 6=2696v3 slot=0:6
rank 7=2696v3 slot=0:7
rank 8=2696v3 slot=0:8
CPU1b.txt的內容
rank 0=2696v3 slot=0:9
rank 1=2696v3 slot=0:10
rank 2=2696v3 slot=0:11
rank 3=2696v3 slot=0:12
rank 4=2696v3 slot=0:13
rank 5=2696v3 slot=0:14
rank 6=2696v3 slot=0:15
rank 7=2696v3 slot=0:16
rank 8=2696v3 slot=0:17
CPU2a.txt的內容
rank 0=2696v3 slot=1:0
rank 1=2696v3 slot=1:1
rank 2=2696v3 slot=1:2
rank 3=2696v3 slot=1:3
rank 4=2696v3 slot=1:4
rank 5=2696v3 slot=1:5
rank 6=2696v3 slot=1:6
rank 7=2696v3 slot=1:7
rank 8=2696v3 slot=1:8
CPU2b.txt的內容
rank 0=2696v3 slot=1:9
rank 1=2696v3 slot=1:10
rank 2=2696v3 slot=1:11
rank 3=2696v3 slot=1:12
rank 4=2696v3 slot=1:13
rank 5=2696v3 slot=1:14
rank 6=2696v3 slot=1:15
rank 7=2696v3 slot=1:16
rank 8=2696v3 slot=1:17
之后跑四個ORCA任務的時候分別指定這四個rankfile,則第一、二個任務就分別在第一個CPU的前9個、后9個核心上跑,第三、四個任務就分別在第二個CPU的前9個、后9個核心上跑,這盡可能減小了四個任務彼此的干擾(但干擾是不可能完全杜絕的)。
3 綁定不同CPU核心跑多任務對耗時的影響
為了測試綁定不同CPU核心對于跑多任務的耗時影響,我選了一個堿基對當測試體系,一共29個原子,在B3LYP-D3(BJ)/def2-QZVP結合RIJCOSX級別下,用筆者的XEON 2696v3雙路機子(36核72線程)進行測試。結果如下
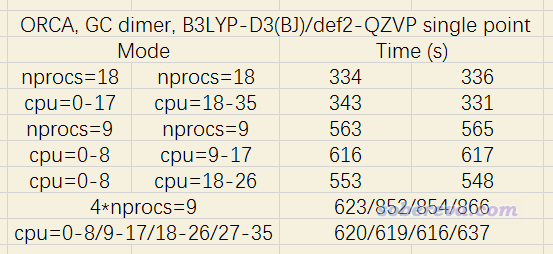
其中諸如nprocs=18代表不對內核進行綁定設置的情況。可見跑兩個18核任務的時候,是否綁定對耗時影響可以忽略。跑兩個9核的任務時,分別在兩個CPU上跑的耗時明顯比讓這倆任務分別占同一個CPU的前9個和后9個核心的耗時要低,顯然后者的情況會對第一個CPU有一定程度的資源爭搶。內核綁定的效果對于同時跑四個任務很明顯,直接跑四個9核的任務的耗時比讓這四個任務綁定不同核心(分別綁定0-8、9-17、18-26、27-35號核心)的耗時高了1/3有余!
這種綁定的做法對于不同類型任務產生的效果不一樣。筆者之前拿ORCA跑了一個環狀體系的AIMD模擬,哪怕只是同時跑兩條對應于不同溫度下的軌跡,每個都給9核,分別綁在兩個CPU上跑的速度都顯著快于不設綁定直接提交兩個任務的情況。還可以觀察到一個現象,如果以普通方式運行,當第二個AIMD任務交上去之后,就會發現ORCA顯示的第一個AIMD任務的每步的耗時增加了很多;而如果兩個任務在運行時分別綁在不同CPU的核心上,則提交第二個任務后,之前正在跑的第一個任務每步的耗時幾乎沒有變化。
總之,對于ORCA用戶,如果經常同時跑多任務的話,不妨留意一下內核綁定問題。對于跑AIMD,我個人總是將多個任務綁定不同內核來跑,哪怕只是同時跑兩個任務。
Gaussian從16版開始支持%cpu設置,可直接控制任務在哪些CPU核心上運行,這在《正確認識超線程(HT)技術對計算化學運算的影響》(http://www.shanxitv.org/392)中我專門提過。筆者也測試了一下在Gaussian中把同時提交的任務指定在不同CPU核心上對速度的影響。還是用堿基對體系,在M06-2X/def2-TZVP下做單點計算,耗時如下

可見是否將不同任務綁在不同CPU核心上運行對耗時基本沒影響,所以Gaussian用戶不需要特意考慮內核綁定問題。如果兩個9線程的任務分別綁定在同一個CPU的前9個和后9個核來跑,速度則會明顯不如照常提交這兩個任務,這和測試ORCA時看到的情況是一致的。