CP2K做雜化泛函計算的關鍵要點和簡單例子
CP2K做雜化泛函計算的關鍵要點和簡單例子
文/Sobereva@北京科音
First release: 2023-Nov-7 Last update: 2024-Feb-18
0 前言
對周期性體系,雜化泛函的計算耗時眾所周知遠高于純泛函。著名的第一性原理程序CP2K不光純泛函的計算超級快,對大體系做雜化泛函計算也非常快(盡管還是遠比純泛函貴),遠遠快于Quantum ESPRESSO (QE)、VASP等純粹基于平面波的程序。CP2K結合像樣的基組做雜化泛函的單點計算,在一般雙路服務器上算到上千原子都沒問題。然而,使用CP2K做高效的雜化泛函計算有很多非常關鍵性的要點必須知道,遠遠不是像Gaussian程序那樣光寫個雜化泛函名字就了事的。然而,筆者經常在網上回答CP2K問題時看到很多人完全不具備這些最基本常識,胡用瞎用CP2K做雜化泛函計算,導致耗時巨高、始終出不來結果、任務崩潰、SCF完全不收斂等各種問題。因此筆者覺得很有必要寫個小文將CP2K做雜化泛函計算的最關鍵常識和要點挨個提一下。Multiwfn程序(http://www.shanxitv.org/multiwfn)具有極其便利的創建CP2K輸入文件的功能,在本文的最后會還用Multiwfn產生C60晶體的CP2K雜化泛函計算的輸入文件作為實際例子。
本文的內容至少對CP2K 2024.1,以及2023-Nov-7及以后更新的Multiwfn是適用的。
筆者在北京科音CP2K第一性原理計算培訓班(http://www.keinsci.com/workshop/KFP_content.html)的“能量的計算及相關問題”部分里講雜化泛函計算遠比本文全面、深入得多,并列舉諸多經驗技巧和例子,還詳細介紹HSE06、CAM-B3LYP、wB97X等各種范圍分離形式的雜化泛函以及revDSD-PBEP86-D3(BJ)等各種雙雜化泛函的用法和要點,使用雜化泛函結合k點計算的要點,歡迎想學習更多知識者關注和參加。
1 CP2K雜化泛函計算的特性
---------
2024-Feb-18更新:以下關于k點的說法已經過時。從2024.1版開始支持了雜化泛函計算時考慮k點,并且可以結合ADMM。此時需要用RI計算HF交換部分。
首先要知道CP2K做雜化泛函計算的一個關鍵不足是不支持考慮k點,因此如果被計算的是周期性體系,晶胞必須大到只考慮gamma點就足夠。如果你要計算的體系的晶胞原本比較小,顯然必須先擴胞到足夠大才行。如果不知道擴到多大夠用,嚴格來說需要做你感興趣的屬性的計算結果隨擴胞倍數的收斂性測試。雖然CP2K能夠對含有非常多原子的超胞做得動雜化泛函計算,但耗時會明顯高于QE等程序對原胞在考慮k點的情況下做雜化泛函計算。
最能充分體現CP2K雜化泛函計算效率優勢的情況是算一些較大分子晶體、MOF、COF等一些大晶胞體系,以及做第一性原理動力學等情況。對小晶胞體系如上所述經過擴胞后也能算,只不過不體現CP2K的長處。
CP2K顯然沒法用雜化泛函算能帶,因為不支持k點,這種目的只能用QE等程序代替。必須用CP2K算的話,應當用CP2K支持的純泛函里算帶隙相對比較好的比如HLE17。
---------
由于雜化泛函遠比普通泛函昂貴,尤其是用于幾何優化、NEB、動力學等涉及到結構變化的任務。因此如果你算的問題用純泛函就足以描述得不錯、用雜化泛函不會帶來明顯好處的話,顯然應該用純泛函。記住,非必要甭考慮雜化泛函,純泛函的耗時僅有雜化泛函的一個微不足道的零頭。對幾何優化、振動分析、NEB等高耗時任務用純泛函,算勢壘、反應能的時候用更好的雜化泛函是可以接受且常見的策略。
周期性體系的雜化泛函計算不僅耗時遠高于純泛函計算,對內存要求更是遠遠高于純泛函計算。經常用CP2K做雜化泛函任務的服務器的內存容量絕對是多多益善,選擇服務器的時候要注意這一點。也別天真地試圖拿個人計算機將就著跑CP2K的雜化泛函計算。
CP2K做雜化泛函計算的前提是編譯時必須帶著libint電子積分庫,否則沒法算雜化泛函中HF交換項中涉及的雙電子積分。CP2K的編譯方法見http://www.shanxitv.org/586。
雜化泛函用的贗勢基組和贗勢就用常見的給PBE等純泛函優化的就可以。從CP2K 9.1開始,data目錄下的BASIS_MOLOPT_UZH和POTENTIAL_UZH文件里還分別給出了專門給PBE0優化的贗勢基組和贗勢,如C的DZVP-MOLOPT-PBE0-GTH-q4和GTH-PBE0-q4,原理上來說它們用于雜化泛函計算會更理想一些(但實際未必有什么優勢)。
2 庫侖截斷
雜化泛函計算之所以比純泛函昂貴得多,在于計算雜化泛函的HF交換項時要計算大量的雙電子積分(two-electron integral, ERI),尤其是對于周期性體系來說,不光要計算晶胞內基函數之間的ERI,還要計算中心晶胞與周圍鏡像晶胞基函數之間的ERI。再加上由于只能算gamma點而晶胞必然較大,原子數、基函數通常非常多,無疑要算的ERI是巨量的。
由于周期邊界條件,原理上來說要計算的ERI是無窮的,顯然這會導致計算無法進行。因此實際計算時必須使用庫侖截斷(Coulomb truncation),也就是將ERI中描述電子庫侖相互作用的1/r算符截斷在某個距離(截斷半徑),超過截斷半徑時1/r視為0,相應地ERI就不需要計算了,這個策略使得ERI的計算數目是有限的。如果你計算的是非周期性體系,由于本身ERI數目就是有限的,因此雖然也可以用庫侖截斷,但這就不是必須的了。
雜化泛函的庫侖截斷的半徑設置顯然既影響耗時也影響結果。截斷半徑越小,要計算的ERI越少,耗時就越低,但結果越偏離泛函原本的精確結果。顯然不能為了一味地節約時間而把截斷半徑設得太小,否則結果會很垃圾。6埃通常是耗時和精度的較好權衡,設得明顯更小會令精度有明顯損失,設得更大并不會令精度有明顯提升卻會增加耗時不少。如果對精度要求很高也可以用8埃,設得更大就完全沒必要了。
要注意像6、8埃這種程度的截斷半徑其實還沒有大到令絕對能量充分收斂,但能量在相互求差時,由截斷半徑帶來的系統性誤差能很大程度抵消。可以認為用不同的截斷半徑相當于用不同的理論方法,直接對比能量的情況必須保持截斷半徑的設置相統一!
值得一提的是,不一定截斷半徑小結果就一定差,有可能截斷半徑造成的對ERI忽略的誤差和泛函本身的誤差相抵消導致恰好對某些體系某些問題的計算比用更大截斷半徑時結果還更好。
截斷半徑應當小于晶胞最短尺寸的一半以免導致得到缺乏物理意義的結果。這里所謂的最短尺寸,是(001)晶面間距、(010)晶面間距、(100)晶面間距三者中的那個最小值。也因此為了能夠使用6埃截斷半徑,晶胞最短尺寸應當大于12埃,如果晶胞不夠大則應當擴胞(即便拋開庫侖截斷問題不談,單從只能計算gamma點這點來說,晶胞也不能過小)。
Multiwfn創建的雜化泛函輸入文件中,若周期性設成了NONE,則不使用庫侖截斷,若是周期性,Multiwfn會自動加上庫侖截斷的設置。如果晶胞最短尺寸夠大,Multiwfn會自動把截斷半徑設為6埃,如果不夠大,則會根據當前晶胞最短尺寸自動設成能設的最大半徑。
以下是庫侖截斷的設置方式,加入到&DFT/&XC里面。POTENTIAL_TYPE TRUNCATED代表用庫侖截斷的1/r算符,CUTOFF_RADIUS設置截斷半徑(埃)。T_C_G_DATA t_c_g.dat是默認的可以不寫,這指定的是庫侖截斷用的gamma函數的數據文件t_c_g.dat,在CP2K的data目錄下。
&HF
&INTERACTION_POTENTIAL
POTENTIAL_TYPE TRUNCATED
CUTOFF_RADIUS 6.0
T_C_G_DATA t_c_g.dat
&END INTERACTION_POTENTIAL
&END HF
3 積分屏蔽
積分屏蔽(integral screening)是指盡可能在不明顯犧牲精度的前提下減少要計算的ERI的量,這對于CP2K雜化泛函計算的耗時和內存使用量有至關重要的影響!上一節的庫侖截斷本身就是一種積分屏蔽策略,CP2K里還有另外兩種非常重要的積分屏蔽方法,也是普遍應用在Gaussian等量子化學程序中的:
(1)利用Schwarz不等式做積分屏蔽:利用Schwarz不等式關系,可以根據數目較少的二指標ERI估計出數目甚巨的三、四指標ERI中哪些數值肯定小于閾值從而可以忽略掉,這可以大幅減少ERI要算的數目(原本總共要算的ERI中占比最大的就是四個基函數序號不同的那些ERI)。閾值通過&DFT/&XC/&HF/&SCREENING中EPS_SCHWARZ設置,此值越大,被忽略的ERI數目越多、計算精度越差。默認的1E-10雖然足夠保證精度,但此時太貴,沒必要。通常設為1E-6就可以了,是精度和耗時的較好權衡,想要精度更好點用1E-8。
(2)結合密度矩陣做積分屏蔽:ERI對能量的貢獻取決于它與特定密度矩陣元的乘積。因此哪怕ERI不是很小,但與之相乘的密度矩陣元很小,那么這樣的ERI也完全不需要計算。CP2K定義了特定方法快速估計一個ERI與相應密度矩陣元乘積值的上限,如果小于上述的EPS_SCHWARZ,則此ERI就會忽略掉。這種依賴于密度矩陣的積分屏蔽默認是關閉的,如果開啟則把&DFT/&XC/&HF/&SCREENING里的SCREEN_ON_INITIAL_P設為T。由于這種積分屏蔽能令耗時巨幅降低,因此我強烈建議總是開啟,也因此Multiwfn產生的雜化泛函的輸入文件里都自動把SCREEN_ON_INITIAL_P設成T。
基于密度矩陣做積分屏蔽有一個極其關鍵的要點是初猜的密度矩陣質量不能太差!然而很多人對此一無所知!默認情況下初始的密度矩陣是CP2K自動做初猜產生的,由于它和SCF收斂時的密度矩陣相差很大、質量很糙,因此此時積分屏蔽通常做得極爛,不僅可以忽略的ERI可能沒忽略,還會把一些重要的ERI給忽略掉,由此可能導致KS矩陣質量很爛、SCF極難收斂。而且忽略哪些ERI是在SCF過程一開始決定好的,即便之后隨著SCF迭代密度矩陣質量不斷變好,也不會由此使得積分屏蔽逐步變得合理,這導致即便最后SCF收斂了,得到的能量的精度也可能很爛。因此當SCREEN_ON_INITIAL_P設T時,必須讀取一個基本合理的波函數當初猜。通常是在雜化泛函計算前先用相同的基組做一個便宜的純泛函計算,比如PBE0計算前先用PBE做一個單點計算,得到記錄了PBE收斂的波函數信息的wfn文件,然后PBE0計算時用SCF_GUESS RESTART,并把WFN_RESTART_FILE_NAME指定成那個wfn文件,以讀取其作為初猜。這不僅使得基于密度矩陣的積分屏蔽可以合理進行,還有一個額外的好處是由于初猜波函數質量較好(至少比默認自動產生的好得多),使得雜化泛函計算時達到SCF收斂所需的迭代次數會比較少,這進一步節約了時間(注意即便拋開ERI計算耗時不談,雜化泛函在構造KS矩陣時花的時間也明顯高于純泛函,因為涉及到密度矩陣元與ERI的大量的乘加操作)。
一般的量子化學程序雖然也基于密度矩陣做積分屏蔽,但不是非得像CP2K這樣得讀取一個像樣的初猜波函數,這是因為它們會根據當前最新的密度矩陣判斷這一輪SCF用的ERI哪些是能被忽略的。CP2K的做法和它們不同,主要是因為CP2K傾向于讓用戶做incore形式的SCF而非一般量化程序一般用的direct形式的SCF,見后文。
當SCREEN_ON_INITIAL_P設T時,對于雜化泛函的幾何優化、分子動力學等任務的續算,要注意光有.restart文件還不行,還必須提供上一步的.wfn文件當初猜波函數,否則也是會由于基于自動初猜的密度矩陣做積分屏蔽非常惡心而令任務無法正常跑下去。
如果你嫌麻煩而不想先做純泛函計算產生收斂的波函數再做雜化泛函計算,那就不要寫SCREEN_ON_INITIAL_P T。對于小體系、小基組特別是非周期性的計算,不基于密度矩陣做積分屏蔽時耗時也不高。而對于計算量較大的雜化泛函計算,則強烈建議不要偷這個懶而多花巨量不必要的時間。
4 ADMM
CP2K還支持其開發者獨創的ADMM (Auxiliary Density Matrix Methods)方法減少要算的ERI數目從而進一步顯著加快雜化泛函的計算,其原理見以下北京科音CP2K第一性原理計算培訓班的ppt。

ppt里提到的主基組就是指平時實際用的基組,諸如DZVP-MOLOPT-SR-GTH。對于不同的主基組,有一些專門構造的與之匹配的ADMM輔助基組,比如MOLOPT系列基組適合搭配的是CP2K的data目錄下的BASIS_ADMM_UZH文件里的那些輔助基組,從小到大依次是admm-dz、admm-dzp、admm-tzp、admm-tz2p。admm-dzp是2-zeta結合極化函數的輔助基組,通常算是保底質量。DZVP-MOLOPT-SR-GTH主基組適合搭配admm-dzp,更好的主基組如TZVP-MOLOPT-GTH結合admm-dzp也可以接受,若結合admm-tzp精度會更好些,這都比起不用ADMM能巨幅節約計算時間和內存。輔助基組的大小與主基組越接近,ADMM給雜化泛函HF交換項帶來的誤差越小,但需要計算越多ERI因而越耗時。如果輔助基組和主基組設為相同的,那么ADMM不會造成任何誤差,相應地也不會節約任何耗時(反倒還會增加一些耗時)。
data目錄下的BASIS_ADMM文件中的FIT3、pFIT3等輔助基組都比較過時了,對元素涵蓋也遠不如BASIS_ADMM_UZH里的完整,因此如今不再建議使用(它們出現在不少官方例子文件和文獻中,如今不要效仿)。目前版本的Multiwfn產生利用ADMM的雜化泛函的輸入文件時默認設的是admm-dzp。
注意前述這些輔助基組都是對GTH贗勢基組用的,千萬別做全電子計算時也用它們。要想全電子計算時用ADMM,可以用(aug-)pcseg系列基組作為主基組,在《在線基組和贗勢數據庫一覽》(http://www.shanxitv.org/309)中介紹的BSE基組數據庫中有和它匹配的(aug-)admm輔助基組,諸如pcseg-2適合搭配admm-2。pcseg是一類構造得很好的對DFT計算非常劃算的基組,《談談量子化學中基組的選擇》(http://www.shanxitv.org/336)里簡要提及了,在《北京科音基礎量子化學培訓班》(http://www.keinsci.com/workshop/KBQC_content.html)里講基組的地方做了具體介紹。
用MOLOPT系列基組做周期性體系的雜化泛函計算幾乎是一定要結合ADMM的,否則極難算得動!因為MOLOPT是完全廣義收縮基組,而CP2K利用的計算源高斯函數(PGTF)之間ERI的libint庫又沒有專門考慮廣義收縮的情況,因此造成等效的PGTF數目甚巨,ERI的數目又與PGTF數目的四次方近似成正比,數目顯然多得恐怖。如果你用片段收縮基組,比如def2-SVP、6-31G**、pcseg-1、pob-DZVP-rev2之類去做雜化泛函計算,由于需要考慮的PGTF數目遠比檔次與之相仿佛的DZVP-MOLOPT-SR-GTH要少,因此ADMM方法不是非用不可,但不用的話耗時會顯著高于DZVP-MOLOPT-SR-GTH搭配admm-dzp的情況。
不能有的原子用ADMM加速計算而有的原子不用。因此如果你用混合基組,其中有的原子用的主基組有ADMM輔助基組,有的沒有,你又想用ADMM,那么沒有ADMM輔助基組的那些原子的輔助基組就只能設定成其主基組。雖然這些原子沒法被ADMM技術加速,但至少其它那部分原子能被加速。
前面提到的各種節約耗時的策略是彼此完全兼容的,同時利用可以最大程度節約時間。即周期性體系雜化泛函計算時一般要用庫侖截斷、利用Schwarz不等式做積分屏蔽、結合密度矩陣做積分屏蔽、開啟ADMM。所有這些設定都會對能量產生影響,因此寫文章的時候最好注明,橫向對比時應統一。
啟用ADMM需要在&KIND里加上BASIS_SET AUX_FIT [輔助基組名],同時增加一行BASIS_SET_FILE_NAME [輔助基組文件名]。并且在&DFT里加入以下內容
&AUXILIARY_DENSITY_MATRIX_METHOD
&END AUXILIARY_DENSITY_MATRIX_METHOD
如果用的是對角化而非OT,還需要在以上字段里加入ADMM_PURIFICATION_METHOD NONE要求不做純化。
5 ERI的儲存和內存使用量的控制
SCF有兩種常見形式,incore SCF是指SCF計算一開始將所有要用到的ERI全都算出來并儲存在內存里,之后SCF每一輪在構造KS矩陣時會直接從內存里讀取ERI而不再重新計算。direct SCF是指SCF每一輪都重新計算要用到的ERI,這也叫on-the-fly方式計算ERI。顯然,incore比direct總耗時低得多,但代價是機子的必須內存非常大,因為要存的ERI通常非常多。在CP2K的雜化泛函計算中,如果你給的內存足夠存得下所有ERI,那么只有SCF第一輪的時候由于要計算所有ERI所以耗時很高,而之后SCF每一輪的耗時就很低了。如果給的內存不夠儲存所有ERI,那么能在內存里存多少ERI就存多少,存的那部分在之后每一輪SCF中會直接讀取,存不下的ERI在每一輪SCF中會重新算,相當于介于incore和direct之間的情況。顯然,做大體系雜化泛函計算時應當盡量在大內存機子上做、分配給CP2K盡可能多的內存,以讓盡可能多的ERI能存到內存中、盡可能減少每輪SCF過程中要on-the-fly計算的ERI的量來節約耗時。
常有人問為什么他做雜化泛函計算時老是卡在SCF剛開始的位置不動,這是因為SCF第一輪肯定是要計算所有需要考慮的ERI,耗時顯然往往很高,對大體系、大基組的情況花一、兩個小時都是常事,看上去好像一直停在這里似的。如果你給的內存較少而導致大部分ERI都得on-the-fly方式去算,那么之后SCF每一輪都得花將近這么多時間,整個任務跑完可能得半天甚至一天時間。如果PRINT_LEVEL設的是MEDIUM,在SCF第一輪算完后就會輸出Number of sph. ERI's calculated on the fly和Number of sph. ERI's stored in-core,前者是之后每一輪SCF都需要重新算的ERI數,后者是已存到內存中而之后不需要SCF每一輪重新算的ERI數。顯然前者相對于后者越小,之后每一輪SCF比第一輪時間少得越多。
CP2K用戶通常默認用popt版本,每個MPI進程在計算HF交換項時最大內存使用量由&DFT/&XC/&HF/&MEMORY里的MAX_MEMORY控制,單位為MB,扣除掉儲存零碎數據的占用量外,其余都用來儲存ERI。MAX_MEMORY與MPI并行進程數的乘積必須小于當前機子空余物理內存量,顯然應當盡量給大以盡可能減少on-the-fly方式算的ERI量,但也不要太頂著頭分配,因為進入HF交換項計算模塊之前CP2K還會占一定量的內存,故要有適當余量。在SCF第一輪不斷往內存里寫入ERI、內存占用量不斷增大的過程中,若空余內存已用完時CP2K還在繼續往里存ERI,CP2K就會馬上崩潰,甚至還可能導致計算機暫時失去響應。所以MAX_MEMORY應當設得恰到好處。
如果空余物理內存很有限,為了能讓MAX_MEMORY能設得比較大,可以減小MPI進程數。為了不因此浪費CPU運算能力,此時可以用psmp版,此時每個MPI進程下屬的OpenMP線程都可以共享這個MPI進程儲存的ERI。
6 雜化泛函的定義方式
這一節簡要說一下雜化泛函怎么正確在輸入文件里定義。對于非周期性體系,比如用PBE0,直接在&DFT里寫上以下內容即可。此時不用庫侖截斷而用完整的1/r算符,EPS_SCHWARZ為默認的1E-10、SCREEN_ON_INITIAL_P為默認的F。
&XC
&XC_FUNCTIONAL PBE0
&END XC_FUNCTIONAL
&END XC
顯然對周期性體系絕對不能簡單寫成上面那樣,至少也得自己去指定為使用庫侖截斷。結合前面的講解,周期性體系PBE0計算的泛函定義部分一般寫為下面這樣。PBE0泛函由75%的PBE交換項+25%的HF交換項+100%的PBE相關項構成,所以需要恰當地定義&PBE里面的參數,并在&HF里用FRACTION指定HF成份。
&XC
&XC_FUNCTIONAL
&PBE
SCALE_X 0.75
SCALE_C 1.0
&END PBE
&END XC_FUNCTIONAL
&HF
FRACTION 0.25
&SCREENING
EPS_SCHWARZ 1E-6
SCREEN_ON_INITIAL_P T
&END SCREENING
&INTERACTION_POTENTIAL
POTENTIAL_TYPE TRUNCATED
CUTOFF_RADIUS 6.0
&END INTERACTION_POTENTIAL
&MEMORY
MAX_MEMORY 3000
&END MEMORY
&END HF
&END XC
有的泛函在&XC_FUNCTIONAL里有特定的字段,可以省得自己去定義細節參數,但HF成份依然必須自己定義,否則相當于只做了殘缺的純泛函計算,結果毫無意義。比如HF成分為10%的TPSSh泛函可以寫為
&XC
&XC_FUNCTIONAL
&HYB_MGGA_XC_TPSSH
&END HYB_MGGA_XC_TPSSH
&END XC_FUNCTIONAL
&HF
FRACTION 0.1
...同上
&END HF
&END XC
更多的泛函定義方式可以直接看Multiwfn產生的相應雜化泛函的輸入文件里的寫法,都是嚴格正確的。
7 一個常見警告:The Kohn Sham matrix is not 100% occupied
做雜化泛函計算,特別是用了ADMM時,很容易在SCF開始后看到The Kohn Sham matrix is not 100% occupied警告。具體原因在https://www.cp2k.org/faq:hfx_eps_warning有介紹,這里就不多說了。對于實際計算來說,看到這個警告時,先把&QS里的EPS_PGF_ORB設為比默認明顯更小的1E-12,如果計算正常,即便還有這個警告也可直接無視。EPS_PGF_ORB設得越小,越無法利用重疊矩陣和KS矩陣的稀疏性節約時間,但這對耗時的影響相對于雜化泛函計算的總耗時來說微不足道。目前版本的Multiwfn產生的雜化泛函的輸入文件里自動就把EPS_PGF_ORB設成了1E-12。
對于晶胞較小的情況,本身矩陣稀疏性就差,開發者建議上來就在&QS里設MIN_PAIR_LIST_RADIUS -1從而完全不利用矩陣的稀疏性節約時間,此時絕對不會再出現那個警告,但比起用EPS_PGF_ORB 1E-12時耗時會高一些。
8 簡單例子:C60分子晶體
最后,這里以C60分子晶體的單點任務作為例子演示一個標準的周期性雜化泛函的計算。如果你還不了解Multiwfn創建CP2K輸入文件的功能,建議先閱讀《CP2K第一性原理程序在CentOS中的簡易安裝方法》(http://www.shanxitv.org/586)。
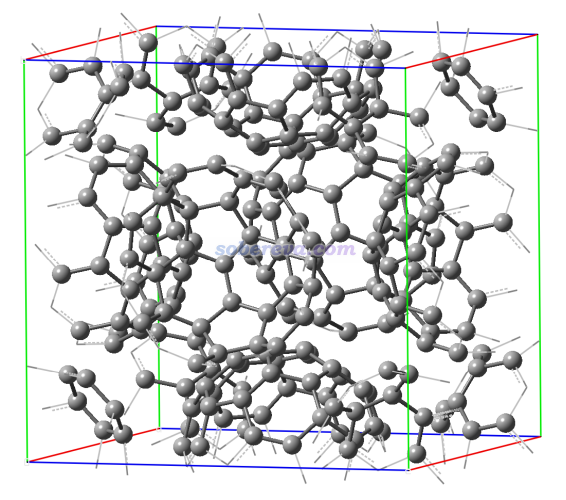
此體系的cif文件和下面涉及的輸入文件都可以在http://www.shanxitv.org/attach/690/file.zip中找到。此體系結構如下所示,一共240個C原子。晶胞邊長是14.07埃,對于分子晶體來說不擴胞的情況下只考慮gamma點可以接受。
啟動Multiwfn,輸入C60.cif的路徑載入之,然后輸入
cp2k
PBE.inp //要產生的PBE計算的輸入文件名
0 //基于默認設置產生輸入文件
現在當前目錄下就有了PBE.inp,對應PBE/DZVP-MOLOPT-SR-GTH單點任務。然后接著在Multiwfn里輸入
cp2k
PBE0.inp //要產生的PBE0計算的輸入文件名
1 //選擇理論方法
-6 //PBE0結合ADMM
0 //產生輸入文件
由PBE0.inp內容可見,Multiwfn自動指定的計算設置完全合適,對應的是PBE0/DZVP-MOLOPT-SR-GTH結合admm-dzp輔助基組、6埃庫侖截斷、EPS_SCHWARZ 1E-6、SCREEN_ON_INITIAL_P T、開啟OT。
手動把PBE0.inp中的WFN_RESTART_FILE_NAME前頭的#去掉并設為PBE-RESTART.wfn,把SCF_GUESS RESTART開頭的#去掉,從而使得PBE0計算時讀取PBE收斂的波函數當初猜。然后根據你的機子的空余物理內存量和要用的MPI進程數設置合適的MAX_MEMORY。
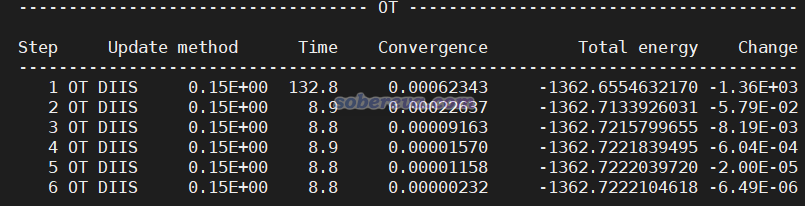
把PBE.inp和PBE0.inp放到同一個目錄下,先運行PBE.inp,算完后當前目錄下就出現了PBE-RESTART.wfn,然后再運行PBE0.inp。在《淘寶上購買的雙路EPYC 7R32 96核服務器的使用感受和雜談》(http://www.shanxitv.org/653)介紹的筆者的2*7R32 512GB雙路服務器上用96核并行、MAX_MEMORY設5000,用CP2K 2023.2 popt版,PBE計算花了8秒,PBE0計算花了178秒。PBE0任務的SCF迭代過程如下所示,可見第一輪耗時較高,由于當前給的內存足夠儲存所有ERI,因而ERI沒有on-the-fly計算的,所以之后每一輪SCF的耗時遠遠低于第一輪。
9 總結
本文把強大的CP2K高效地做雜化泛函計算的各方面要點進行了介紹,以避免初學者對各種關鍵信息毫不知情而憑感覺胡用瞎用。本文的內容也充分體現出用Multiwfn產生CP2K輸入文件非常容易,令研究者從復雜的輸入文件編寫中充分解放,但這絕不意味著CP2K的使用者就可以對關鍵性技術細節毫不知情,否則會各種踩坑、白浪費時間、算出無意義的結果。CP2K用戶必須掌握的知識、要領遠多于大部分其它計算程序。筆者開設的北京科音CP2K第一性原理計算培訓班(http://www.keinsci.com/workshop/KFP_content.html)可以使得學員完整系統透徹掌握全部這些知識。