小測Tesla C2050在amber11上的GPU加速性能
nVidia正在做tesla免費試用活動,國內由AMAX負責,提供5個小時的測試時間,通過SSH遠程登陸,機子是XEON 5520*2, 16GB, Tesla C2050*2。用它們的機子測了下Tesla C2050在amber11下的性能,基本與amber官網上的數據吻合,略微偏低一點。下面數據中測Tesla時的Amber11的pmemd.cuda(即GPU加速版pmemd)是那邊預先編譯好的,所用編譯器、數學庫未知,pmemd.cuda是SPDP模式,即單精度運算為主,雙精度運算為輔,此模式在不使精度有明顯損失下盡可能迎合當前Tesla單、雙精度相對運算能力以達到最好的性能;測Q6600時用的是MKL+ifort編譯的Amber10和內部版本的Amber11(性能估計和正式版應該沒區別),mpich2 4核并行,Fedora7。
測試的是Amber官方提供的測試包中的三個體系。
(1)JAC_NPT, 23558 atoms
這是個比較典型的蛋白+顯式水體系,參數為
&cntrl
ntx=5, irest=1,
ntc=2, ntf=2,
nstlim=25000,
ntpr=500, ntwx=1000,
ntwr=10000,
dt=0.002, cut=8.,
ntt=1, tautp=10.0,
temp0=300.0,
ntb=2, ntp=1, taup=10.0,
ioutfm=0,
/
由計算時間估算的每天能跑的長度如圖所示
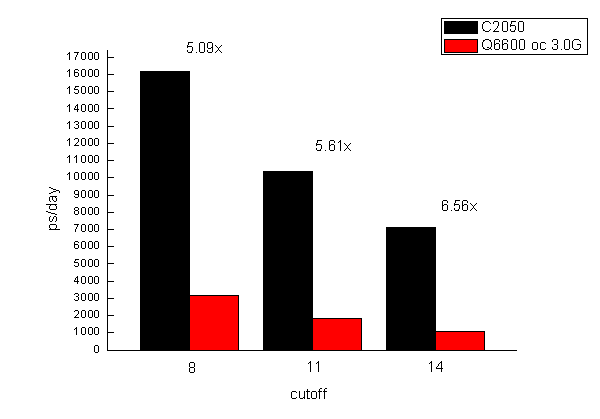
C2050性能是Q6600 oc 3.0G的5.09倍。cutoff加大后性能衰減得都比較厲害,cutoff=14時速度只有=8時的一半。但cutoff越大,加速比越大,cutoff=14時前者是后者性能6.56倍。雖然pmemd.cuda利用GPU加速,但運行時也占滿一個CPU核心的計算量,所以GPU加速時的運算能力不能100%算在GPU上,CPU多少會影響整體性能,AMAX機子上C2050性能稍遜于amber官方數據和CPU的差異也不免有一定關系。
上面的圖中Q6600是在Amber10下面的pmemd跑的,但amber11的pmemd性能并沒有提升,所以上述對比是公平的。
Q6600 oc 3.0,cut=8 amber10(pmemd) 3176ps/day
Q6600 oc 3.0,cut=11 amber10(pmemd) 1846ps/day
Q6600 oc 3.0,cut=14 amber10(pmemd) 1083ps/day
Q6600 oc 3.0,cut=8 amber11(pmemd) 3153ps/day
Q6600 oc 3.0,cut=11 amber11(pmemd) 1838ps/day
Q6600 oc 3.0,cut=14 amber11(pmemd) 1079ps/day
目前amber11不支持多GPU加速是一個遺憾。不過,可以調用不同的支持CUDA的設備同時跑多個任務,只需要在執行的命令后用-gpu x參數即可,x是CUDA設備的ID號,由0~32,x=-1是默認的,即調用顯存最多的CUDA設備。考慮到多CUDA設備執行時顯存與內存的數據交換量比單CUDA設備執行時更大,可能對帶寬造成些壓力,成為瓶頸,遂測試兩個pmemd.cuda任務同時執行時的性能,即分別用-gpu 0和-gpu 1來執行:
pmemd.cuda -gpu 0 16119ps/day
pmemd.cuda -gpu 1 16000ps/day
單pmemd.cuda 16179ps/day
可見,兩個pmemd.cuda任務同時執行時性能與單pmemd.cuda任務執行時幾乎無異,降低只有1%左右,至少說明在此平臺上對于同時發揮兩個C2050的能力不構成瓶頸。
雖然官方稱軌跡使用binpos比使用mdcrd運行速度更快而建議用binpos,不過在C2050的測試中速度優勢只有1%,當然這與ntwx有很大關系。
(2) Myoglobin_GB, 2492 atoms
這是個GB模型下小蛋白體系,參數為
&cntrl
imin=0,irest=1,ntx=5,
nstlim=500000,dt=0.002,ntb=0,
ntf=2,ntc=2,tol=0.000001,
ntpr=1000, ntwx=1000, ntwr=50000,
cut=9999.0, rgbmax=15.0,
igb=1,ntt=0,nscm=0,
/
結果為
c2050 46426ps/day
Q6600 oc 3.0, amber10(pmemd) 2298ps/day
Q6600 oc 3.0, amber11(pmemd) 2304ps/day
在隱式溶劑模型下GPU加速性能提升得明顯比顯式溶劑更大,加速后是之前性能的20.15x,算是質的飛躍。但是,隱式溶劑模型終究適用范圍小,在無關緊要的地方炫耀性能的提升意義不大。然而,作為硬件銷售者nVidia,自然喜歡炫耀這性能20倍的提升來吸引更多眼球。
(3) Nucleosome_GB, 25095 atoms
更大的在GB模型下的體系,參數為
&cntrl
imin=0,irest=1,ntx=5,
nstlim=10000,dt=0.002,ntb=0,
ntf=2,ntc=2,tol=0.000001,
ntpr=100, ntwx=200, ntwr=50000,
cut=9999.0, rgbmax=15.0,
igb=1,ntt=0,nscm=0,
/
結果為
c2050 1003ps/day
Q6600 oc 3.0, amber10(pmemd) 21ps/day
Q6600 oc 3.0, amber11(pmemd) 21ps/day
靠CPU完全跑不起來。此時GPU加速性能優勢更加凸顯,是純CPU運算時速度的47.76倍!明顯,GB下體系越大GPU加速優勢越明顯。不過,應當冷靜地認識這夸張的數據的實際價值,不應被沖昏頭腦,目前pmemd.cuda的局限性還不少,很重要的就是還不支持cutoff,或者說cutoff必須大于體系尺寸,所以例子用的都是cutoff=9999.0。在常用的cutoff范圍中,比如=15,提升幅度又能有多少呢?從顯式水的測試中也看到了,加速比與cutoff是正相關的。
(4) Cellulose 408609 atoms
此體系很大,參數為:
&cntrl
ntx=5, irest=1,
ntc=2, ntf=2, tol=0.000001,
nstlim=10000,
ntpr=1000, ntwx=1000,
ntwr=10000,
dt=0.002, cut=8.,
ntt=0, ntb=1, ntp=0,
ioutfm=1,
/
&ewald
dsum_tol=0.000001,
nfft1=256,nfft2=128,nfft3=128,
/
執行時一開始即提示顯存不夠,運算不能。C2050盡管有3G顯存,卻仍然不能滿足要求。然而官網上擁有4G顯存的C1060卻能正常運行。我很懷疑如果C2050顯存也是4G,能否正常運行,我感覺未必能行。這顯示出當前CUDA加速的一個問題,即遇見大體系顯存不足就根本不能跑,而且對顯存容量要求量遠比使用CPU運行時內存要求量要大,純CPU跑這個體系,四核并行時有2G內存就足夠了。
其實Fermi架構的Tesla相對于價格是其1/10的、單精度運算能力相同的同核心Geforce從性能上來說,比如C2050相對于GTX 470來說,優勢就是1.顯存大(GTX470為1.25GB) 2.有專用的雙精度運算單元,性能達到單精度的1/2(Fermi系列核心的Geforce產品專用的雙精度單元被屏蔽,只能靠SFU做雙精度運算,性能為單精度的1/8,GTX460由于SFU相對數量有所增加,為1/6)。顯存不夠就不能跑的這個問題,雖是弊病,倒也成了增加Tesla銷量,避免用戶圖便宜選擇Geforce的觸媒。
Fermi架構的Tesla雙精度運算能力的優勢目前沒派上太大用場,雖說GPU不支持雙精度則pmemd.cuda就完全不能跑(即便是全部計算使用單精度的SPSP模式,但SHAKE部分還是需要有雙精度運算能力),但G200系列核心及之后的nvidia卡從高端到低端都支持雙精度,而且動力學可接受的精度要求不高,適當的優化就避免對雙精度運算能力的要求。對雙精度要求最大的是量化軟件,但是目前這方面還不給力,徹頭徹尾的支持CUDA加速的TeraChem用過的人甚少,且尚處萌芽期,而且收費,曾免費發放過的beta版也無從下載。Firefly雖然目前在微擾等計算上能支持,但畢竟能被加速的功能還很少,有待成熟。與AMAX的人溝通時據說是有不少用戶希望Gaussian支持了GPU加速再買他們的產品,的確,這將是有誘惑力的,但據稱Frisch是很守舊的人,若是nVidia的人不主動與他們聯姻,恐怕Gaussian14出了都未必能支持GPU加速,而其它主流量化軟件開發者透露明確意圖支持GPU加速的寥寥。總之,nVidia要想靠Tesla雙精度運算能力來說服計算化學工作者購買,必須得更加重視量化這一塊。
也跑了跑AMAX機子上自帶的NAMD測試腳本(NAMD為2.7b),結論如下
2*XEON5520 0.476ns/day
2*c2050 2.353ns/day
加速比與顯式水下的pmemd.cuda差不多。
最后談談現階段對購買Tesla的看法。
如果用來跑amber,且體系不太大,比如在十萬個原子以內,而且是個人用,沒有必要用Tesla C2050,買一塊1G版本的GTX460就行了,目前一千五上下。而個別廠商,比如銘瑄的GTX460就有2G版本,價格也就高出二三百元,更值得購買(盡管這牌子比較寨)。如果多人用或同時跑多個任務,可以多買幾塊,目前雙路XEON通常搭配的5520芯片組可以支持PCI-E 2.0 4*8x,即最多四塊同時使用。C2050現在零售差不多18500人民幣(如果是購買搭配Tesla的AMAX公司的服務器產品,從報價上看一塊C2050大概合27000元),跑動力學軟件性能并不會比同核心的GeForce更好,價格卻是其10倍,也只有很大體系當GTX460顯存不足時才能發揮優勢(相對于其2G版本優勢就更小了)。而這20000元如果自己攢的話,購買兩臺雙路8核機子了,而且支持的軟件、功能不受局限。雖然C1060已經是過時產品,沒有C2050的專用的雙精度單元、沒有顯存ECC、沒有DVI-I輸出端等新加入的雜項功能,單精度性能比GTX460還差,但是顯存大(4G),價格相對C2050便宜很多,零售約八千多,如果要跑幾十萬原子大體系,也可以考慮。
至于想通過Tesla來加速量化軟件,購買時機還遠未成熟,估計2年后應該會有一些主流量化程序的某些關鍵性模塊支持GPU加速,那時,一方面目前產品價格會降下來,另一方面新的Tesla的雙精度運算能力應該還會有所加強,而且是否那時Tesla比Geforce對量化程序加速能力強大到值得多花那么多錢還不好說。另外,那個時候格局不好預測,雖然CUDA先走一步,但是在量子化學這方面的作為卻明顯遲于MD、Docking、序列對比等軟件,沒有優先占領有利地形。AMD雖然在GPU加速方面顯著落后一步(盡管在N年前GPU加速Folding@HOME時先走一步),但隨著OpenCL、DirectCompute的成熟,屆時或許有量化程序用OpenCL支持GPU加速,而使其目前用途很有限的FireStream系列產品用于GPU加速也很有競爭力,Tesla或許將不是唯一的選擇。而且Intel也醞釀著Larrabee系列產品(盡管不時有計劃擱淺的消息傳出,但仍在進行),基于Atom的48核已經提供給一些研究單位試用,由于基于x86架構,若是能早日推出,哪怕性能輸于同時代不少,若是價格合理,由于量化代碼無需改動就能用,明顯會有更強的競爭力。所以需要拭目以待,不要急于出手。
PS: 想當年參加IDF2007的時候現場看到Intel 80核峰值性能飆到2T,但3年后卻只看到悄悄發布一個弱化的48核版本,Larrabee一再延期,2年內能推出就很不錯了。