談談體數據1:介紹體數據
談談體數據1:介紹體數據
文/Sobereva 2012-Feb-12
前言:《談談體數據》是一系列帖子,寫這些帖子的目的,就是讓讀者了解什么是體數據,尤其是想讓計算化學工作者開闊視野,領會到經常分析的諸如軌道波函數等值面圖與計算機圖形學領域、醫療成像領域及其它計算科學界涉及的普遍意義的體數據之間的本質聯系,能夠進而利用比起計算化學領域的可視化軟件更強大的通用體數據渲染軟件繪制出漂亮乃至藝術級的和化學相關的體數據。
1 體數據的基本概念
體數據(Volume data)記錄了某個三維或多維空間范圍內各個離散的格點上的數值,格點數據(Grid data)是體數據的另一種稱呼。在計算化學界常用的Gaussian型cube文件就是體數據的一種記錄方式。格點間隔區域上的數值可以用離它最近的格點數值來表示,或者使用插值方法通過臨近格點數值來生成。
體數據在計算機圖形學、生物醫學、地質學、計算物理/化學、材料學等諸多領域都有重要用途,將它圖形化后可以產生漂亮的效果,或通過直觀分析得到有價值的信息。下面給出幾個例子
圖1 美國大氣研究中心模擬的伊莎貝爾龍卷風

圖2 旋轉X射線掃描得到的人腦右邊的動脈瘤
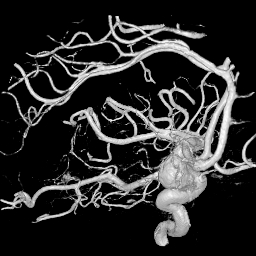
圖3 氰化氫分子的電子定域化函數圖
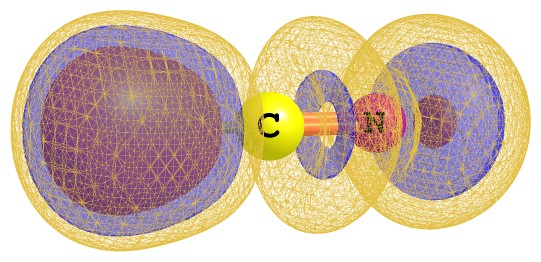
圖4 模擬火焰燃燒效果

除了用于可視化,一些科學研究中的數值方法也要借助于格點數據。比如在計算化學中,有一類盆積分方法就是基于格點數據的(用于AIM、電子定域性分析),定量分子表面分析(可用于研究分子反應位點、預測熱力學性質、相互作用強度等)也要借助于格點數據。
最常見的體數據記錄的是三維笛卡爾空間分布的立方格點上的標量數據。在一些領域,也使用更高維的空間,或者納入時間的維度,即(x,y,z,t)形式。有時也用其它坐標,如曲線坐標、球面坐標,以及其它類型的格子,比如三斜格子、八面體格子、四面體格子等。每個點上的數據也不都是標量,可以是向量數據(如電場),也可以含有多個量的數值(比如氣溫、氣壓、濕度、空氣中各物質的濃度)。
2 獲得體數據的方法
獲得體數據的方法主要分兩類,一類是測量得到的數據,另一類是計算模擬得到的數據。
能獲取體數據的測量技術/儀器有很多,它們需要將測量到的信號進行重新處理后才能得到體數據。比如醫學上用的核磁共振(MRI)、計算機輔助X光斷層攝影(CT)、正電子發射斷層攝影(PET)、彌散張量成像(DTI);材料學用的超聲波掃描顯微鏡(C-SAM);生物學上用的激光掃描共聚焦顯微鏡(CLSM)、冷凍電子顯微鏡;還有化學上的X光衍射等。不同技術適合不同組成、尺度的物質和不同問題的研究。
計算機模擬可以直接得到很多類型的體數據。比如量子化學上,可以計算軌道波函數、電子密度、電子定域性函數、外磁場下電流密度分布;分子模擬中可以計算不同粒子的密度分布;氣象學/海洋學等領域利用流體力學可以模擬溫度、速度、密度分布等等。
值得一提的是,斷層攝影得到的體數據有很多非常有趣的用途,斷層掃描儀如同一臺昂貴的大玩具。比如可以了解一個橘子里有沒有籽
了解儲蓄罐里有多少鋼镚

如果有一臺斷層掃描儀,自家的盆景也可以掃描成體數據

實際上,安檢用的就是類似這樣的技術。
一些測量或模擬得到的體數據文件可以在一些數據庫中下載到,比如
V3程序的數據庫:http://www9.informatik.uni-erlangen.de/External/vollib/
VolrenApp程序的數據庫:http://www.gris.uni-tuebingen.de/edu/areas/scivis/volren/datasets/datasets.html
VolrenApp程序的數據庫(新):http://www.gris.uni-tuebingen.de/edu/areas/scivis/volren/datasets/new.html
Stenford的數據庫:http://graphics.stanford.edu/data/3Dscanrep/3Dscanrep.html
3 體數據的可視化
體數據的可視化的基本流程是:
1 獲得體數據:如上一節所介紹的。
2 體數據的變換:將得到的體數據去噪,過濾異常值,調節數值分布范圍,差值或向下采樣,與其它體數據融合等。
3 數據分類(data classification):這個詞有些抽象,原意是通過對數據分類使數據能夠最高效地被使用。而對于體數據的可視化,這個詞是指通過設定合適的參數,讓感興趣的區域能夠清晰地展現出來。具體來說,以顯示等值面方式來顯示時,就是指設定一個合適的等值面數值(isovalue);若是用直接體渲染方式,則是設定不同空間或數值范圍內的點的色彩(RGB值)和透明度(Alpha值)。
4 產生圖像:有很多方法,將在下面介紹。
產生體數據圖像的方法主要分為兩類:
1 直接體渲染(direct volume rendering, DVR)包括光線投射算法(Ray-casting)、錯切-變形法(Shear-warp)、頻域體繪制法(Frequency Domain)、拋雪球算法(Splatting)、Sabella法、V-buffer法等等,這些方法可以直接得到屏幕上像素點的色彩值。目前最為常用的是光線投射算法。
光線投射算法的基本原理是:從屏幕的每個像素徑直引出射線,一部分或全部射線將會穿過體數據的各個格子,根據射線依次穿過的位置上的色彩值和不透明值(通過與之相鄰的點的在數據分類階段由用戶設定的色彩和不透明度進行插值來得到)對色彩和不透明度進行依次累積,直到光線透過了體數據區域或者不透明度為1時停止。將累積下來的色彩和不透明度相乘,結果就是發出這條射線的像素的色彩值了。在累積過程中還有一些與權重相關的細節問題這里就不提了。
光線投射法與另一個耳熟能詳的光線追蹤法(Ray-tracing)的區別在于后者發出的光在碰到物體時會反射、折射,不考慮穿越過程的色彩的累積,而只考慮相交處的情況。而光線投射法發出的光會一直徑直前進并累積色彩,也因此不會產生陰影效果。
2 間接體渲染(indirect volume rendering, IVR)。用這種方式得到的是等值面圖,即這個面上各處的數值都等于用戶設的isovalue值。先要構建等值面模型(由一堆三角形構成),再按照標準的圖形學渲染方法得到圖像,因此是間接的。計算化學的可視化軟件幾乎全都是用等值面方式展現體數據,若使用mesh方式顯示等值面,就可以看到構成它的三角形了,比如本文圖3里最外層的那層等值面。
構建等值面的方法非常多,最常用的是Marching cubes方法,這里簡單介紹一下基本原理。這種方法是先判斷各個點上數值是否大于isovalue,如果大于就記作1,如果小于就記作0。一個格子是由6個點組成的,掃描每個格子,若6個點不都為1也不都為0,就代表這個格子就穿過了等值面。總共有2^6=256種穿越方式,如果考慮對稱性的話,可以簡化為15種,如下圖所示:
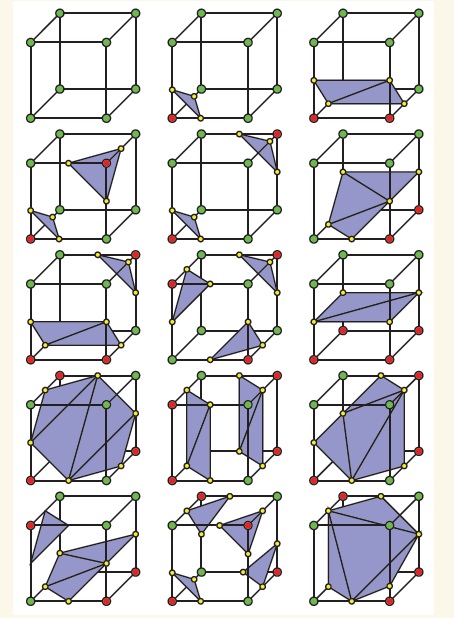
綠色和紅色頂點代表是否這個點的數值大于isovalue。紅點和綠點之間的連線顯然跨過了等值面,通過線性插值方法近似得到的與等值面相交的點用黃點表示,這些黃點就是等值面上的點了。每三個這樣的點構成一個紫色三角形。所有的穿過等值面的格子產生的紫色三角形連起來就構成了等值面。
Marching cubes的一個最大問題是模糊性問題,這會造成生成的等值面在個別地方出現錯誤。若通過這種IVR方式顯示血管時由于等值面構建問題,導致誤診為血管梗塞而做搭橋手術,結果手術失敗使患者死亡,那就糟糕了。有很多人提出了不同方法去解決這個問題,有興趣的讀者可參考綜述文章Computers & Graphics, 30, 854。另一種構建等值面的方法是Marching tetrahedron,這種方法是把每個格子再切成5、6個或多個三角形然后以類似方法構建等值面上的三角形,這種方法比Marching cubes的優勢在于沒有了模糊性,而且等值面穿越三角形的方式只有2^4=16個,通過對稱性可簡化為三種,大大方便了編程。但缺點是會產生比Marching cubes更多的頂點,加重渲染負擔,而且三角形的質量更加惡化,總有很多三角形面積非常小(對于等值面模型質量幾乎沒貢獻,故浪費了計算量)。寡人更偏好Marching tetrahedron方法,日后會專門寫一個帖子詳細介紹原理和算法的實現。
對于數據量很大的情況,第一次構建等值面會花一定時間,一旦等值面模型構建好了,再去旋轉縮放視角就非常快了,不需要再去訪問體數據了。除非又調整了isovalue,則又得需重新構建一遍模型。DVR方式下每更新一幀都需要重新算一遍,因此旋轉縮放視角的過程的計算量會比IVR大很多。好在光線投影算法逐漸被轉移到了GPU中實現,這使得計算速度大為加快,旋轉縮放等操作可以實時完成。
等值面圖雖然可以比DVR得到的圖更清楚、準確地定量研究體數據,但是圖形效果上做不到DVR那么炫(但使用DVR的話得在數據分類階段更費心思調節),起碼是對于目前這些計算化學可視化軟件來說。因此,想做出令人眼前一亮的富有藝術氣息的體數據圖,計算化學工作者們應當學會那些支持DVR模式的通用的、高級的體數據可視化工具。
另外,考察體數據也可以用二維截面圖,這能更清晰地展現特定平面上的細節,但沒法同時考察整個空間的體數據,需要不斷挪動、旋轉截面,難以把握整體。
4 體數據的精度、格式
體數據沒有固定的格式。不同程序有各自的私有體數據格式,以不同精度、順序、壓縮方式記錄數據,并包含一些特定信息,如格子定義、注釋等。一些程序影響力比較大則其格式通用性會強一些,比如OpenDX的.dx格式。不同研究領域也有本領域的比較通用的格式,比如計算化學界的Gaussian類型的cube文件,可參考此文的介紹:《Gaussian型cube文件簡介及讀、寫方法和簡單應用》(http://www.shanxitv.org/125)。
唯一一個跨領域通用的格式是raw格式,這種格式非常簡單,就是將全部格點數據以二進制方式按順序寫入,沒有經過任何額外處理,且連格子設定都沒有在其中記錄,也沒有定義數據類型。因此,如果沒有額外的信息記錄各個維度的格點數和平移矢量的長度比例,那么這種數據根本沒法利用。高檔相機和一些掃描儀等圖像采集設備也都能輸出raw格式,這種平面圖像的raw格式和體數據的raw格式類似,也是沒有額外信息也未經壓縮而直接寫入的二進制數據,但區別是它記錄的是二維數據點上的數據而非三維或更高維,而且它記錄的一定是色彩信息(灰度信息,或者紅、綠、藍的數值)。
raw形式儲存的體數據一般都是使用單字節(8bit數據)或雙字節(16bit數據)的整數來表示數值大小的,數據范圍分別是0~255和0~65535(假設是無符號整數,后同)。一般這種精度范圍足矣區分出不同區域數值大小了。很少見到以4字節整數方式記錄(數據范圍0~4294967296),因為圖形化顯示本來也達不到那么高的精確度,而且測量儀器輸出精度也有限。以單精度或雙精度浮點數記錄的raw格式也很少見到。
在一些計算模擬領域中生成的體數據是浮點數,可能有很大的數值范圍,而且數值分布也不均勻。比如電子密度是隨著遠離原子核呈指數型下降的,原子核附近電子密度比化學鍵區域大得多。對于cube文件,由于是用浮點數儲存的,所以儲存在這樣的格式里沒什么問題,但如果轉存為比如單字節的整數型raw格式就會越界了。因此,就需要對數據范圍進行移動、拉伸,這樣才能讓數據范圍落在0~255以內,并且分布均勻,使作圖方便。
體數據為了避免單個文件太大不好處理,或者受限于格式定義,有時會將某個維度拆成單獨的文件存放。比如隨時間變化的數據可能每個時間點都有單獨的體數據,斷層掃描的體數據可能把每一層的數據保存為一個個二維面數據。